

Fundamentos e Programação de Banco de Dados
Introdução teórica aos fundamentos do curso completo, que será disponibilizado em breve.


Este módulo apresenta a estrutura do curso, os objetivos profissionais da disciplina e o papel do banco de dados no desenvolvimento de sistemas contemporâneos. Ele estabelece a base conceitual necessária antes de entrar em modelagem, SQL e programação em banco de dados.
Ao final deste módulo, você compreenderá:
como funciona a área de banco de dados hoje
quais habilidades o mercado espera
como a disciplina será construída
qual é o papel do SQL na engenharia moderna
quais são as etapas da formação prática em dados
O que significa estudar Banco de Dados hoje
Durante muito tempo, estudar banco de dados significava aprender a administrar servidores corporativos grandes, estáveis e silenciosos, quase sempre instalados dentro de datacenters físicos. O estudante era treinado para operar sistemas como Oracle ou SQL Server em ambientes fechados, onde a principal preocupação era manter integridade, disponibilidade e desempenho sob controle. O papel do DBA era semelhante ao de um guardião de arquivo histórico: proteger, organizar e garantir que nada se perdesse.
Esse cenário mudou profundamente.
Hoje, estudar banco de dados não é aprender apenas a armazenar informação. É aprender a organizar a realidade em estruturas que possam ser consultadas, transformadas e reinterpretadas continuamente por sistemas inteligentes, aplicações distribuídas e modelos analíticos. O banco deixou de ser um depósito. Ele passou a ser o eixo de coordenação entre serviços.
Quando uma aplicação recomenda um filme, sugere uma rota, detecta fraude em um cartão ou organiza o feed de uma rede social, há um banco de dados sustentando decisões em tempo real. Não é exagero dizer que o banco de dados deixou de ser uma camada técnica invisível e passou a ser a linguagem estrutural através da qual sistemas entendem o mundo.
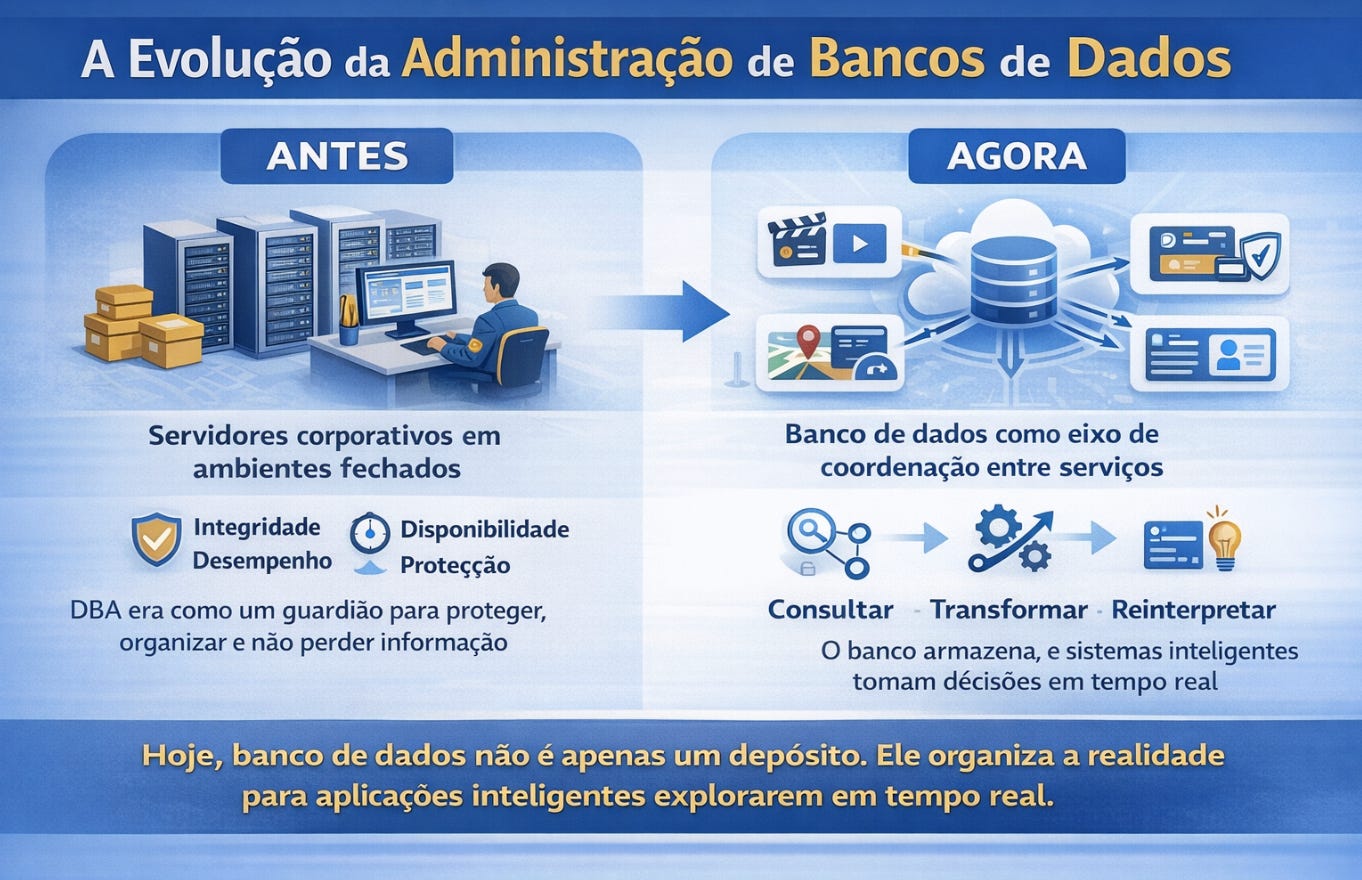
Por isso, estudar banco de dados hoje significa aprender a estruturar informação de forma que ela permaneça confiável mesmo quando atravessa múltiplos sistemas. Significa compreender como representar entidades do mundo real dentro de modelos formais. Significa decidir o que deve ser persistido, o que deve ser derivado e o que deve ser descartado.
Essa mudança também transformou o perfil do profissional.
O antigo especialista em banco de dados trabalhava isoladamente, muitas vezes distante das equipes de desenvolvimento. Já o profissional atual transita entre áreas. Ele participa da construção de APIs, da modelagem de aplicações, da organização de pipelines analíticos e da definição de métricas de negócio. Mesmo quando não assume formalmente o título de engenheiro de dados, ele opera dentro da mesma lógica estrutural.
Um analista de dados precisa compreender como as tabelas foram modeladas para interpretar corretamente um indicador. Um desenvolvedor backend precisa entender como índices afetam desempenho antes de escalar uma aplicação. Um cientista de dados depende da qualidade da estrutura relacional para garantir que seus modelos não estejam aprendendo padrões inexistentes. Um arquiteto de sistemas precisa decidir quando utilizar bancos relacionais, quando utilizar armazenamento colunar e quando trabalhar com estruturas orientadas a eventos.
Nesse contexto, aprender banco de dados é aprender a pensar estruturalmente.
Essa forma de pensamento não se limita a memorizar comandos SQL. Ela envolve reconhecer dependências entre entidades, antecipar inconsistências antes que apareçam e prever o impacto de decisões de modelagem sobre o comportamento futuro de um sistema. É uma habilidade silenciosa, mas poderosa. Quanto mais cedo ela é desenvolvida, mais natural se torna navegar por sistemas complexos.
Outro aspecto fundamental é que o banco de dados passou a ocupar uma posição central dentro das arquiteturas modernas em nuvem. Em vez de existir como um servidor único controlado manualmente, ele passou a funcionar como serviço distribuído, replicado automaticamente e integrado a ferramentas de processamento em larga escala. Isso significa que compreender banco de dados hoje também envolve compreender latência, escalabilidade, particionamento e consistência distribuída, mesmo que de forma introdutória.
Ao estudar banco de dados, o estudante começa a perceber que dados não são apenas registros. Eles são relações entre eventos, decisões e interpretações. A forma como essas relações são representadas determina o tipo de pergunta que será possível fazer no futuro. Uma modelagem mal construída limita a inteligência do sistema antes mesmo de ele entrar em produção. Uma modelagem bem construída amplia possibilidades analíticas por anos.
SQL permanece como o principal instrumento dessa interação. Ele atravessou décadas de evolução tecnológica sem perder relevância porque expressa algo mais profundo do que comandos operacionais. SQL é uma linguagem declarativa que permite descrever o que se deseja descobrir sem especificar exatamente como o sistema deve executar essa descoberta. Essa característica faz dele uma ponte entre raciocínio humano e execução computacional.
Por isso, estudar banco de dados hoje não significa aprender uma ferramenta específica. Significa aprender a construir estruturas que sustentam aplicações, análises e decisões. Significa desenvolver uma sensibilidade para organização da informação que acompanha toda a carreira técnica, independentemente do cargo escolhido.
Quem aprende banco de dados aprende a enxergar sistemas por dentro. E essa habilidade, uma vez adquirida, raramente desaparece. Ela passa a influenciar a maneira como se programa, como se analisa e até como se pensa sobre problemas complexos fora da tecnologia.
Arquitetura de Banco de Dados
Antes de aprender SQL, antes de modelar tabelas, antes mesmo de instalar um banco, existe uma pergunta silenciosa que orienta toda a disciplina: onde exatamente os dados vivem dentro de um sistema? Entender arquitetura de banco de dados é responder essa pergunta com clareza técnica.
Quando falamos em arquitetura de banco de dados, estamos falando da forma como a informação percorre o caminho entre três mundos diferentes. Primeiro existe o mundo do usuário, onde surgem ações como clicar, pesquisar, comprar, cadastrar ou comentar. Depois existe o mundo da aplicação, que interpreta essas ações como lógica. Por fim existe o mundo do armazenamento, onde essas ações se transformam em registros persistentes. A arquitetura é o desenho dessas conexões.
Um Sistema Gerenciador de Banco de Dados, ou SGBD, funciona como o mediador desse processo. Ele não é apenas um local onde os dados ficam guardados. Ele decide como os dados são escritos, como são recuperados, quem pode acessá-los, em que ordem operações acontecem e como evitar conflitos quando várias pessoas interagem ao mesmo tempo com a mesma informação. Em outras palavras, o SGBD é um organizador ativo da memória digital.
Para compreender esse papel, é importante perceber que armazenar dados não significa apenas salvar textos dentro de arquivos. Um banco precisa garantir que aquilo que foi salvo continue coerente mesmo após falhas elétricas, interrupções de rede, acessos simultâneos ou erros humanos. Essa garantia é o que diferencia um banco de dados de uma simples pasta cheia de planilhas.
Ao estudar arquitetura, começamos entendendo como os sistemas armazenam dados fisicamente. Embora pareça invisível para quem escreve consultas SQL, existe uma estrutura interna organizada em páginas, blocos e índices que determina a velocidade com que a informação pode ser localizada. Cada consulta feita ao banco atravessa esse território subterrâneo antes de retornar um resultado. Quanto melhor essa estrutura for compreendida, mais fácil se torna escrever consultas eficientes.
Outro aspecto central dessa etapa é entender a diferença entre bancos relacionais e não relacionais. Bancos relacionais organizam dados em tabelas conectadas por relações explícitas. Eles são excelentes quando precisamos de consistência, integridade e clareza estrutural. Já bancos não relacionais surgiram para lidar com volumes massivos de dados distribuídos e formatos menos previsíveis, como documentos, grafos ou eventos em tempo real. Não se trata de escolher um modelo “melhor”, mas de compreender qual arquitetura responde melhor a cada tipo de problema.

A arquitetura cliente-servidor aparece como o primeiro grande modelo de organização desses sistemas. Nesse formato, o banco de dados não está dentro do programa que o usuário utiliza. Ele vive em outro processo, muitas vezes em outra máquina, aguardando requisições. A aplicação conversa com o banco através de protocolos específicos, envia comandos SQL e recebe respostas estruturadas. Essa separação permite que múltiplas aplicações compartilhem o mesmo conjunto de dados sem comprometer a integridade das informações.
À medida que os sistemas evoluíram, surgiram camadas intermediárias entre aplicação e banco. Essas camadas são responsáveis por traduzir estruturas de programação em consultas SQL, controlar conexões simultâneas e organizar transações. Elas formam o que chamamos de camada de persistência. Mesmo que o estudante ainda não trabalhe diretamente com frameworks ou APIs, compreender a existência dessa camada ajuda a entender por que dados raramente são acessados diretamente pelo código de interface.
No cenário contemporâneo, a arquitetura de banco de dados também inclui a presença da nuvem como elemento estrutural. Bancos deixaram de ser instalados exclusivamente em servidores locais e passaram a existir como serviços distribuídos, capazes de escalar automaticamente conforme a demanda cresce. Isso significa que o armazenamento deixou de ser um recurso fixo e passou a ser uma infraestrutura elástica. O profissional moderno precisa compreender que a arquitetura não termina na máquina onde o banco roda, mas se estende por redes inteiras de processamento.
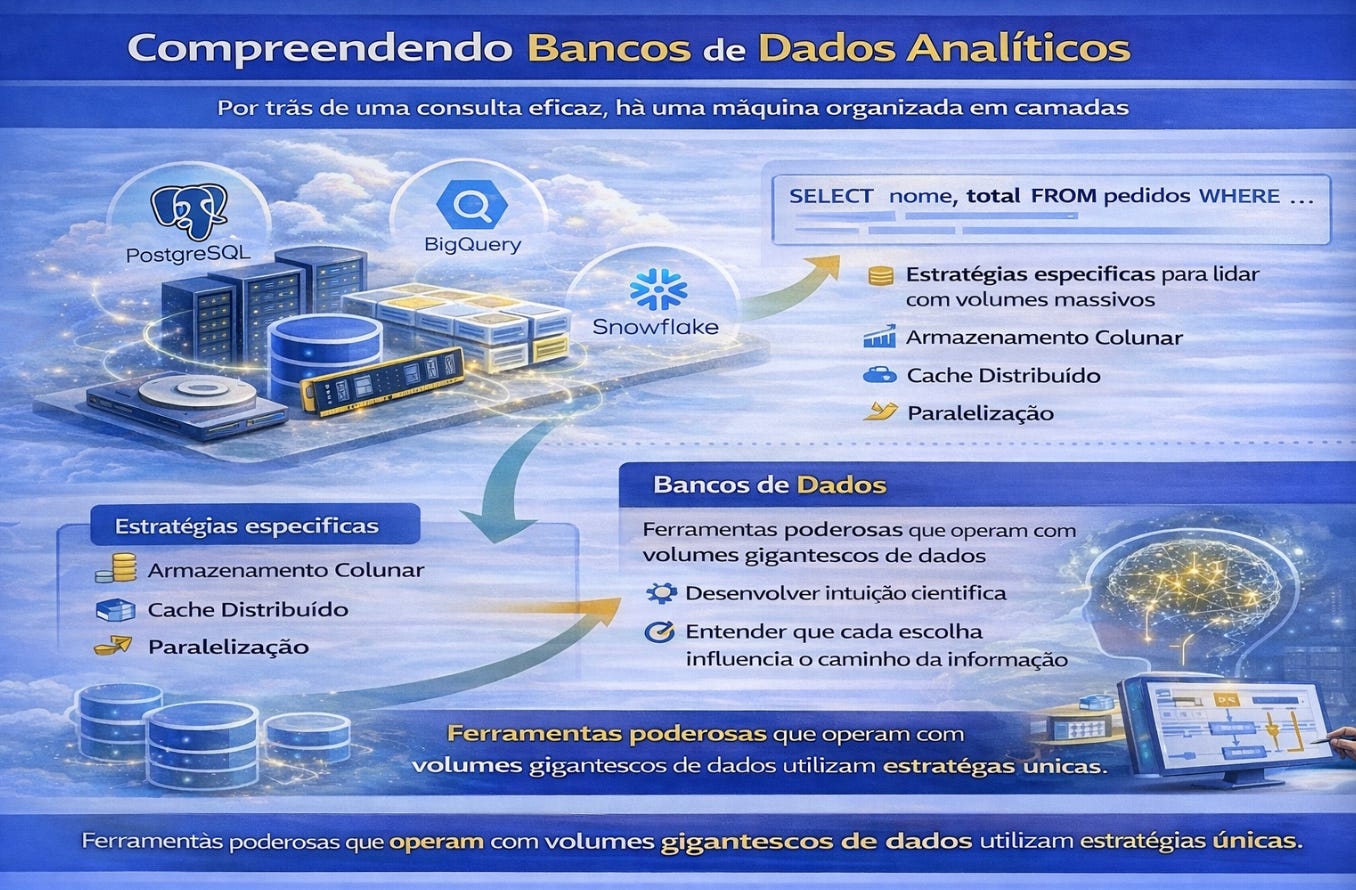
Ferramentas como PostgreSQL, MySQL e SQL Server continuam sendo fundamentais porque permitem visualizar claramente os princípios estruturais dos bancos relacionais. Ao mesmo tempo, plataformas como BigQuery, Snowflake e Redshift representam a transição para ambientes analíticos distribuídos, onde consultas operam sobre volumes imensos de dados com latências reduzidas. Estudar arquitetura hoje significa compreender esse espectro completo, desde o banco local utilizado em desenvolvimento até sistemas capazes de processar bilhões de registros.
Essa etapa do curso não ensina apenas nomes de tecnologias. Ela constrói um mapa mental. Sem esse mapa, SQL vira uma sequência de comandos isolados. Com ele, cada consulta passa a fazer sentido dentro de um sistema maior, como se o estudante finalmente enxergasse a planta baixa do edifício onde antes caminhava apenas pelos corredores.
Modelagem de Dados
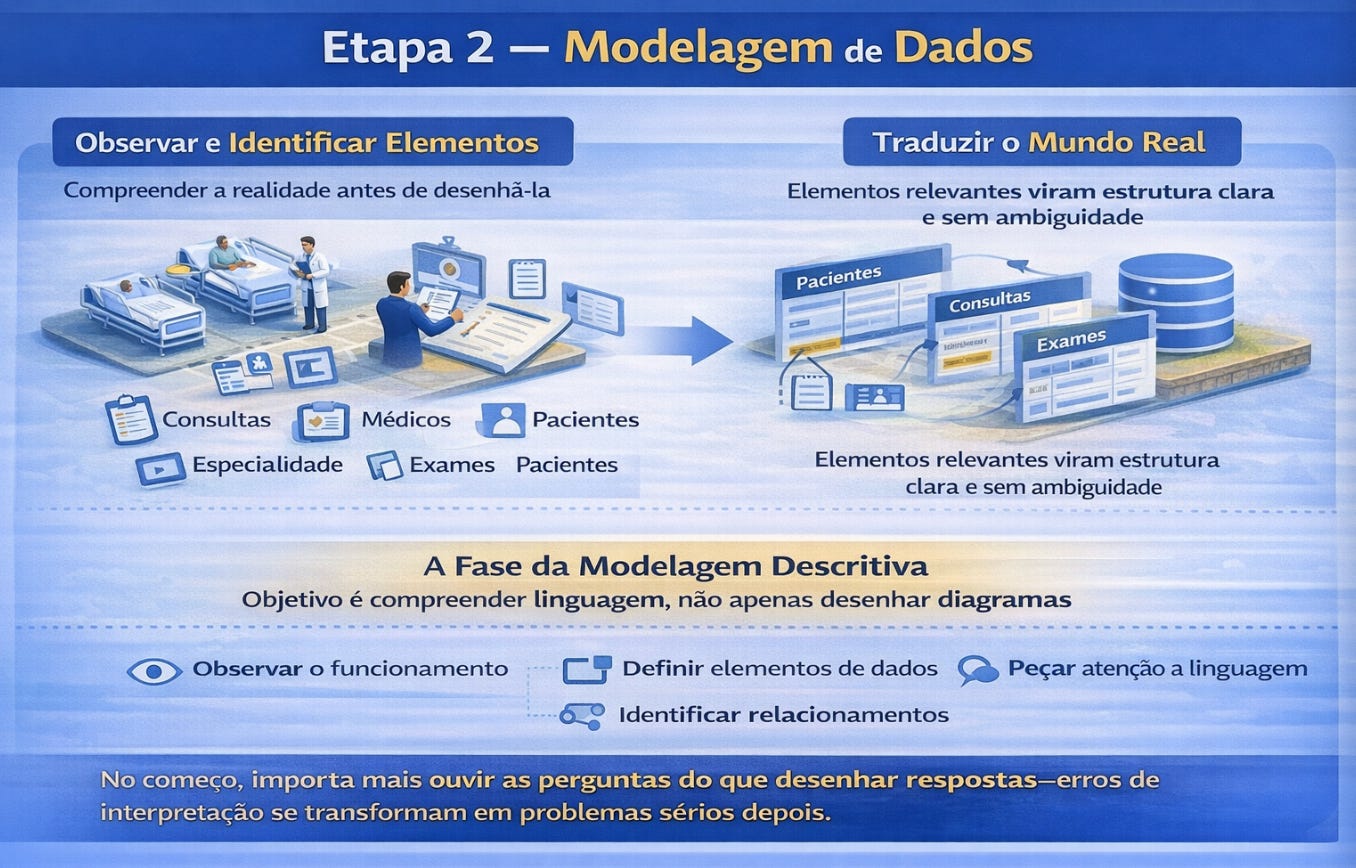
Se a arquitetura de banco de dados ensina onde os dados vivem, a modelagem de dados ensina como eles passam a existir com sentido. Modelar dados é traduzir o mundo real para uma linguagem estrutural que o sistema consiga compreender sem ambiguidades. É uma atividade de interpretação antes de ser uma atividade técnica.
Toda modelagem começa com um exercício silencioso de observação. Antes de criar tabelas, o profissional precisa identificar quais elementos da realidade são relevantes para o sistema que está sendo construído. Um hospital, por exemplo, não precisa apenas armazenar nomes de pacientes. Precisa representar consultas, médicos, especialidades, horários, exames, prescrições e vínculos entre essas entidades. Cada decisão sobre o que entra ou não entra no modelo determina o tipo de pergunta que será possível responder no futuro.
A modelagem descritiva é o primeiro passo desse processo. Ela acontece ainda antes de qualquer diagrama formal. Nesse momento, o objetivo é compreender o domínio do problema. O modelador observa como a organização funciona, quais informações circulam entre setores, quais decisões dependem dessas informações e quais registros precisam existir para que essas decisões sejam confiáveis. Trata-se menos de desenhar estruturas e mais de compreender linguagem. Muitas vezes, erros de banco de dados nascem de interpretações equivocadas de termos aparentemente simples. A palavra “cliente”, por exemplo, pode significar uma pessoa física em um sistema e uma empresa em outro. Se essa diferença não for percebida no início, ela se transforma em inconsistência estrutural depois.
A modelagem conceitual surge quando essa compreensão inicial começa a ganhar forma. Nesse estágio, as entidades principais do sistema passam a ser representadas explicitamente. Uma entidade não é apenas uma tabela futura. Ela é um objeto do mundo real que possui existência própria dentro do domínio analisado. Um pedido existe independentemente do pagamento. Um aluno existe independentemente da matrícula em uma disciplina. Um produto existe independentemente de estar em estoque. Reconhecer essas independências é o que permite construir modelos coerentes.
As relações entre entidades também aparecem nesse momento. Elas revelam como os elementos do sistema interagem entre si. Alguns relacionamentos são simples e diretos. Outros carregam significado operacional profundo. Quando um sistema registra que um paciente realizou um exame em determinada data, ele não está apenas armazenando três valores. Ele está registrando um evento que conecta pessoas, procedimentos e tempo. Essa conexão precisa ser representada de maneira precisa para evitar ambiguidades futuras.
A modelagem lógica representa a transição entre o mundo conceitual e o mundo técnico. Aqui, as entidades deixam de ser apenas ideias estruturais e passam a assumir forma de tabelas com atributos definidos. Nesse estágio, decisões importantes começam a aparecer. É necessário escolher quais campos representam cada entidade, quais serão obrigatórios, quais poderão ser nulos e quais devem permanecer únicos. Também é nesse momento que surgem as chaves primárias, responsáveis por garantir identidade para cada registro armazenado.
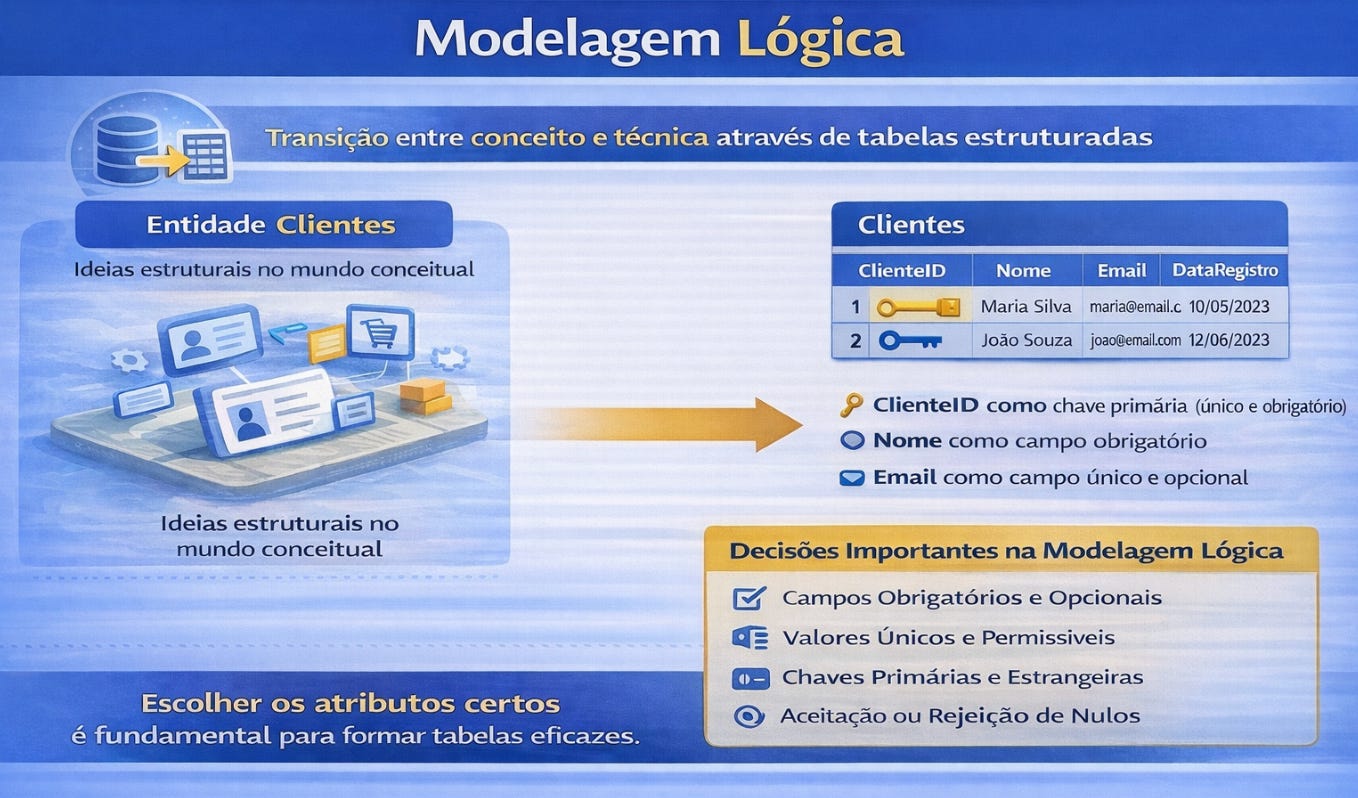
A definição dessas chaves não é apenas uma formalidade técnica. Ela estabelece a forma como o sistema reconhece individualmente cada elemento que armazena. Quando um banco define que um código identifica exclusivamente um cliente, ele está criando uma referência permanente que permitirá conectar esse cliente a pedidos, pagamentos, acessos e históricos futuros. Sem essa identidade estrutural, o banco perde capacidade de manter coerência ao longo do tempo.
A integridade referencial aparece como consequência natural dessa etapa. Ela garante que relações entre entidades permaneçam válidas mesmo quando o sistema cresce. Se um pedido pertence a um cliente, o banco precisa impedir que esse cliente desapareça sem que o pedido seja tratado adequadamente. Essa proteção evita que o banco acumule registros órfãos, inconsistentes ou contraditórios. Mais do que uma regra técnica, a integridade referencial é uma forma de preservar a narrativa interna do sistema.
A normalização surge então como um mecanismo de refinamento estrutural. Ela não existe para tornar o modelo mais “acadêmico”, mas para evitar redundâncias que podem gerar inconsistência. Quando uma mesma informação aparece repetida em vários lugares, ela se torna difícil de manter. Pequenas divergências começam a surgir e, com o tempo, o sistema passa a conter múltiplas versões da mesma verdade. Normalizar significa reorganizar os dados de modo que cada informação exista apenas onde realmente pertence.
Esse processo exige sensibilidade. Normalizar excessivamente pode tornar consultas complexas demais. Normalizar pouco pode gerar inconsistência. O equilíbrio depende sempre do tipo de sistema que está sendo construído. Modelagem não é aplicação mecânica de regras. É uma negociação entre clareza estrutural e eficiência operacional.
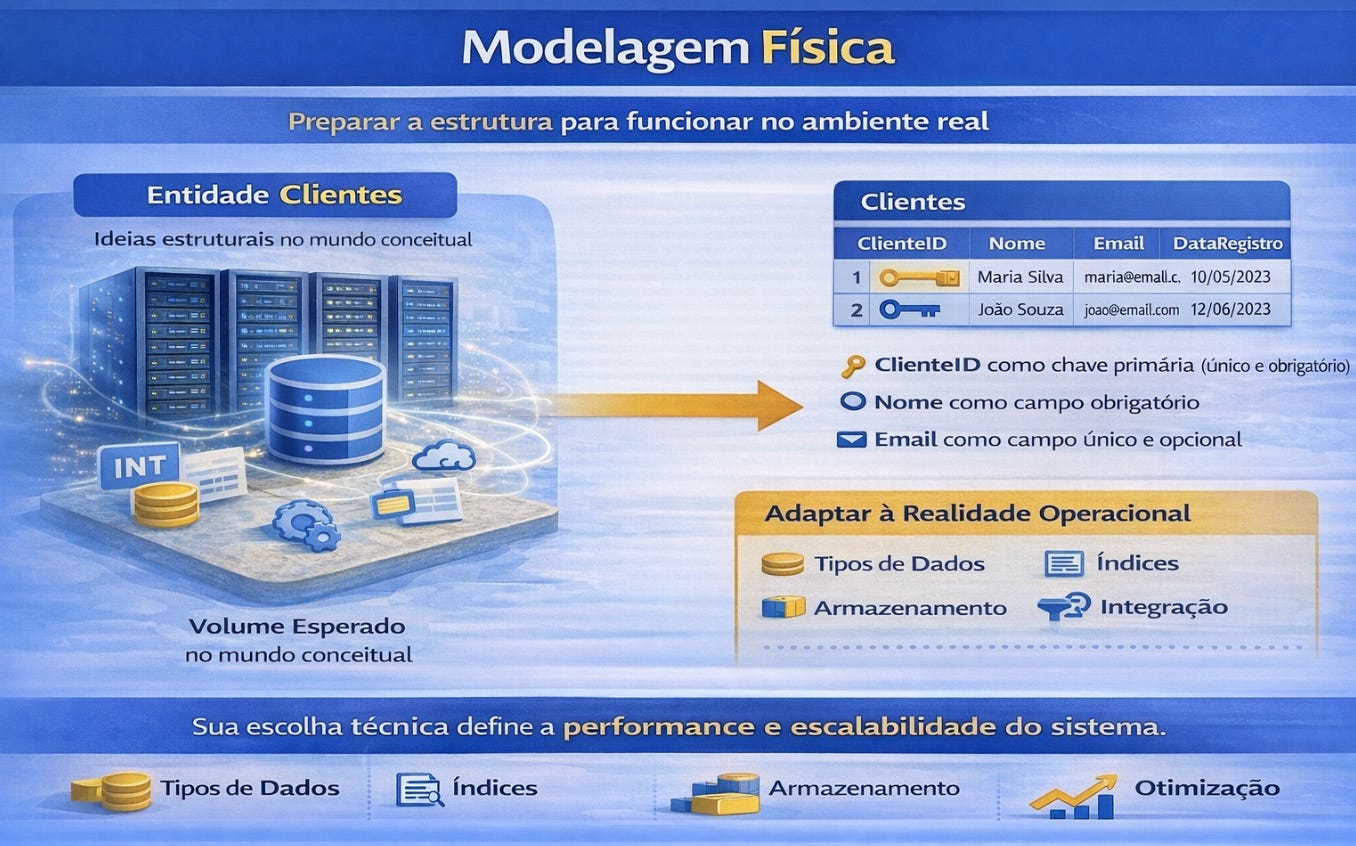
A modelagem física representa o momento em que a estrutura finalmente encontra o ambiente onde será executada. Aqui entram decisões relacionadas a tipos de dados específicos, índices, estratégias de armazenamento e otimização de acesso. Embora essas escolhas pareçam técnicas, elas têm impacto direto na velocidade com que o sistema responde às consultas e na capacidade de crescimento da aplicação ao longo do tempo.
Em ambientes modernos, essa etapa também considera aspectos como volume esperado de dados, frequência de leitura, padrões de atualização e integração com pipelines analíticos. Um modelo que funciona bem para um sistema administrativo pequeno pode se tornar inviável em um ambiente com milhões de registros diários. Por isso, a modelagem física não é apenas a implementação do modelo lógico. Ela é a adaptação desse modelo à realidade operacional.
Quando essas quatro camadas de modelagem são compreendidas como partes de um mesmo processo, algo importante acontece. O banco deixa de ser visto como uma coleção de tabelas e passa a ser entendido como uma representação estruturada de um domínio real. Nesse momento, o estudante começa a perceber que modelar dados não é apenas preparar um sistema para funcionar. É definir a forma como esse sistema será capaz de compreender o mundo que pretende registrar.
Estruturas físicas e lógicas de banco de dados
Depois que aprendemos a modelar entidades e relações, surge uma pergunta inevitável: onde exatamente essas estruturas passam a existir dentro do banco? A modelagem descreve o que será armazenado. As estruturas físicas e lógicas explicam como isso é realmente mantido, organizado e recuperado pelo sistema.
Existe uma diferença importante entre a forma como enxergamos o banco de dados e a forma como ele funciona internamente. Quando olhamos uma tabela em uma ferramenta gráfica, vemos linhas organizadas em colunas com aparência limpa e intuitiva. Para o SGBD, porém, aquilo não é uma tabela no sentido visual. É um conjunto de blocos distribuídos em páginas de armazenamento que precisam ser lidos e reorganizados continuamente para responder às consultas. A tabela é uma abstração lógica. O armazenamento é uma realidade física.
Compreender essa diferença transforma completamente a forma como alguém escreve SQL.
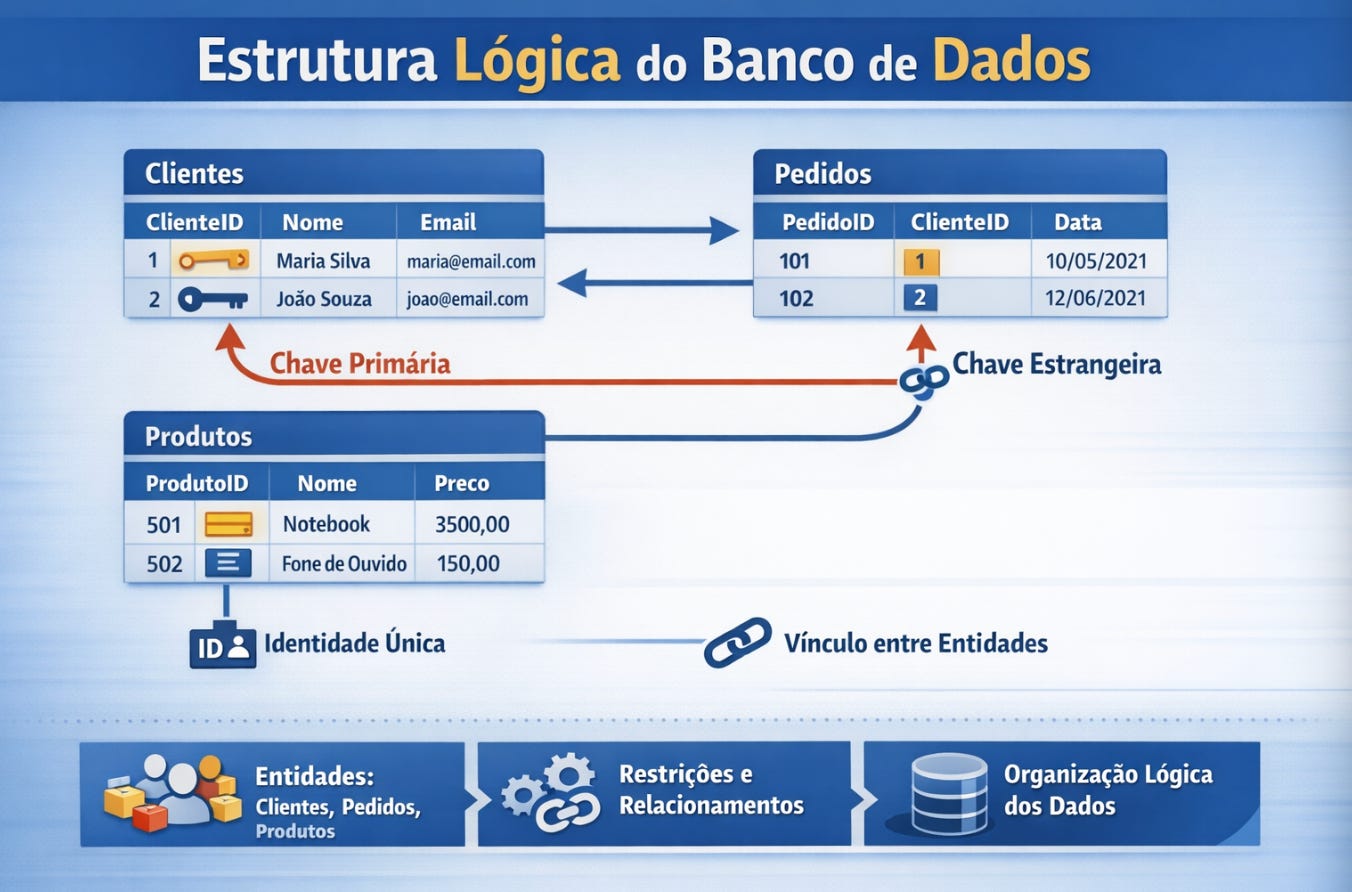
A estrutura lógica é a camada que o desenvolvedor enxerga diretamente. Ela inclui tabelas, colunas, relacionamentos e restrições. É nesse nível que definimos entidades como clientes, pedidos ou produtos. A lógica organiza significado. Ela determina o papel de cada dado dentro do sistema. Quando criamos uma chave primária, por exemplo, estamos estabelecendo identidade. Quando criamos uma chave estrangeira, estamos estabelecendo vínculo entre entidades. Tudo isso pertence ao plano lógico.
Já a estrutura física responde a outra pergunta: onde esses registros ficam guardados no disco e como o banco consegue encontrá-los rapidamente depois.
Internamente, bancos não armazenam dados como listas contínuas. Eles organizam informações em páginas de dados, que são blocos de memória com tamanho fixo. Cada página pode conter vários registros, e essas páginas são distribuídas pelo disco conforme o volume cresce. Quando uma consulta solicita dados, o banco não “procura linhas”. Ele localiza páginas. Esse detalhe muda completamente a percepção de custo de uma consulta.
Se uma consulta exige leitura de centenas de páginas espalhadas pelo armazenamento, ela será lenta mesmo que retorne poucos registros. Se consegue acessar poucas páginas organizadas de forma eficiente, pode ser extremamente rápida mesmo com grandes volumes de dados. É por isso que entender páginas de dados não é um detalhe técnico irrelevante. É compreender o ritmo interno do banco.
Entre o disco e a execução da consulta existe outra camada silenciosa chamada buffer. O buffer funciona como uma área intermediária de memória onde páginas recentemente acessadas permanecem armazenadas temporariamente. Sempre que possível, o banco tenta responder consultas usando páginas já presentes nesse espaço. Isso evita leituras repetidas em disco, que são muito mais lentas. Em sistemas com grande volume de acesso, o comportamento do buffer influencia diretamente a performance geral.
Quando uma consulta SQL é enviada ao banco, ela não é executada imediatamente da forma como foi escrita. Antes disso, o sistema cria um plano de execução. Esse plano é uma estratégia interna que determina quais caminhos serão percorridos para localizar os dados solicitados. O banco avalia múltiplas possibilidades e escolhe aquela que estima ser a mais eficiente com base em estatísticas internas. Duas consultas visualmente semelhantes podem gerar planos completamente diferentes dependendo da presença de índices, do tamanho das tabelas ou da distribuição dos valores armazenados.
É nesse ponto que entram os índices, que funcionam como atalhos estruturais dentro do banco. Um índice não armazena novos dados. Ele reorganiza referências existentes para que possam ser localizadas com mais rapidez. Imagine procurar um nome em um livro sem índice alfabético. Seria necessário ler página por página até encontrá-lo. Com um índice, a busca se torna quase imediata. No banco de dados acontece algo semelhante. O índice cria caminhos alternativos para acessar registros sem percorrer toda a tabela.
Entretanto, índices não são gratuitos. Cada índice criado precisa ser mantido atualizado sempre que novos dados são inseridos, alterados ou removidos. Em sistemas com grande volume de escrita, índices excessivos podem reduzir desempenho em vez de melhorar. Por isso, entender quando criar um índice é tão importante quanto saber criá-lo.
O armazenamento físico também influencia diretamente o comportamento do banco ao longo do tempo. À medida que registros são inseridos e removidos, páginas podem se fragmentar. Essa fragmentação aumenta o número de operações necessárias para recuperar dados relacionados. Muitos sistemas corporativos executam rotinas periódicas de reorganização exatamente para reduzir esse efeito silencioso que degrada performance gradualmente.
Na prática profissional, dominar essas estruturas significa deixar de escrever consultas “que funcionam” e passar a escrever consultas que funcionam bem mesmo em escala. Uma consulta eficiente não depende apenas de sintaxe correta. Ela depende de como o banco interpreta aquela sintaxe internamente.
Esse conhecimento se torna ainda mais importante em ambientes analíticos modernos. Ferramentas como PostgreSQL, BigQuery ou Snowflake operam com volumes gigantescos de dados e utilizam estratégias específicas de armazenamento colunar, paralelização e cache distribuído. Embora o estudante não precise dominar todos esses mecanismos imediatamente, compreender que eles existem muda a forma como ele pensa consultas desde o início.
Quando essa etapa é assimilada, o banco deixa de parecer uma caixa preta. Ele passa a ser percebido como uma máquina organizada em camadas, onde cada decisão de modelagem e cada consulta escrita influenciam diretamente o caminho percorrido pela informação. É nesse momento que o estudante começa a desenvolver uma intuição rara e extremamente valiosa: a capacidade de prever o comportamento do banco antes mesmo de executá-lo.
Instalação e configuração do ambiente de banco de dados
Existe um momento decisivo na formação de qualquer pessoa que estuda banco de dados: o instante em que o banco deixa de ser um conceito teórico e passa a existir como um sistema vivo rodando em sua própria máquina. Até esse ponto, tudo acontece no nível da modelagem e da linguagem. A partir daqui, o estudante começa a compreender que trabalhar com dados significa também construir o território onde esses dados vão habitar.
Instalar um banco de dados não é apenas executar um instalador. É entender como um sistema persistente nasce, como ele se organiza dentro de um sistema operacional e como aplicações passam a conversar com ele. Esse processo marca a transição entre aprender sobre bancos e trabalhar com bancos.
Nos cursos antigos, era comum utilizar Oracle 10g ou SQL Server 2008 porque eram padrões corporativos dominantes. Hoje, o cenário mudou. PostgreSQL tornou-se o ambiente mais completo para aprendizado técnico profundo, não apenas por ser gratuito, mas por oferecer recursos avançados que aparecem também em bancos comerciais. MySQL continua extremamente presente em aplicações web. SQL Server permanece relevante em ambientes corporativos. SQLite aparece como uma alternativa leve, ideal para experimentação local e aplicações embarcadas. Além disso, a virtualização por containers introduziu uma nova forma de trabalhar com bancos que reduz drasticamente a complexidade de instalação.

Quando um banco é instalado pela primeira vez, ele cria uma estrutura interna invisível ao usuário comum. Diretórios são preparados para armazenar páginas de dados, arquivos de log são configurados para registrar transações e processos de escuta são iniciados para aceitar conexões externas. A partir desse momento, o banco deixa de ser apenas software e passa a ser um serviço ativo. Isso significa que ele permanece disponível mesmo quando nenhuma aplicação está conectada, aguardando comandos.
Compreender essa ideia de banco como serviço é fundamental. Diferente de programas comuns que abrem e fecham quando usamos, o banco permanece em execução contínua. Ele administra memória, controla concorrência entre usuários e mantém mecanismos de recuperação prontos para restaurar consistência em caso de falha. Essa persistência operacional é o que permite que sistemas reais funcionem de forma confiável durante anos.
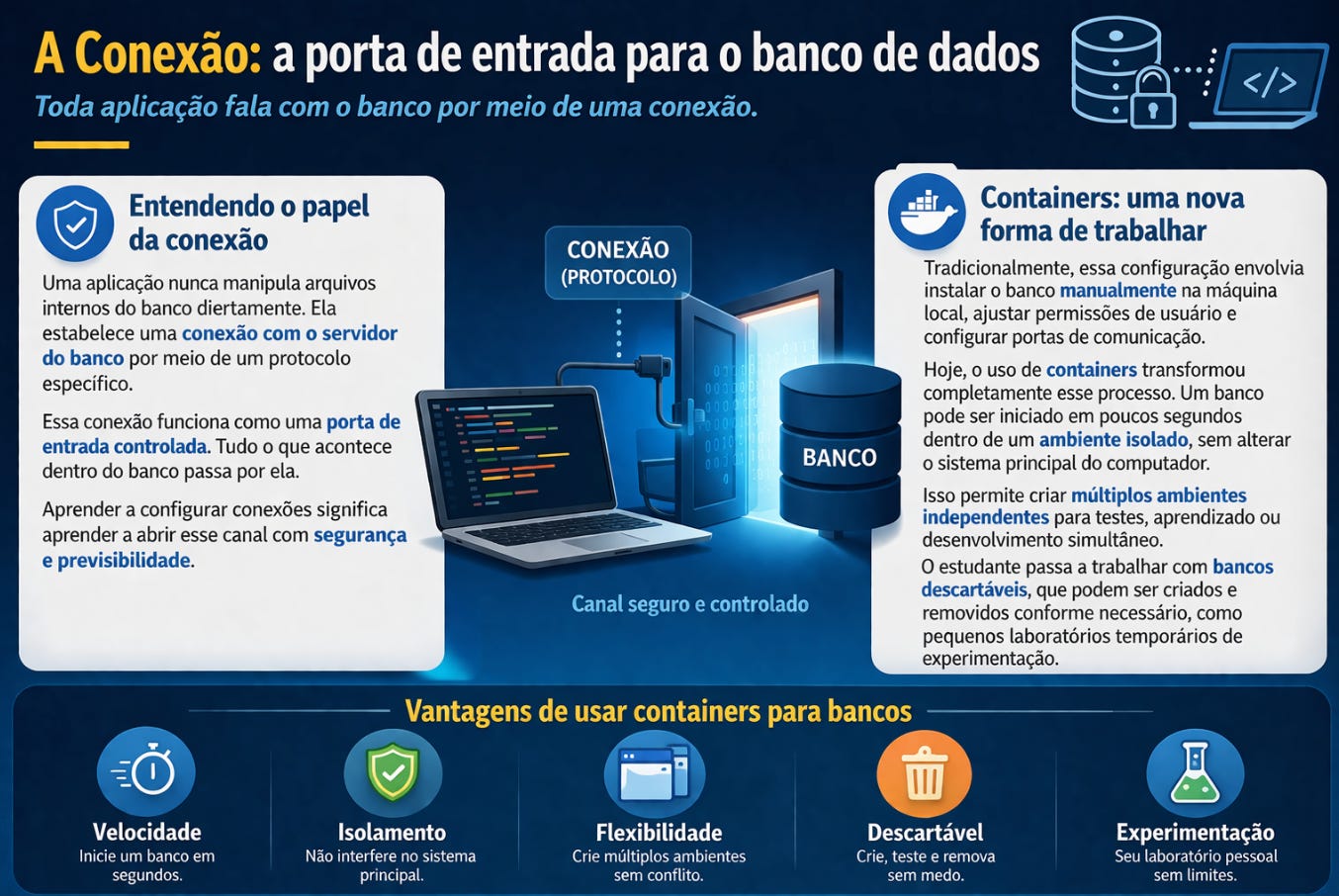
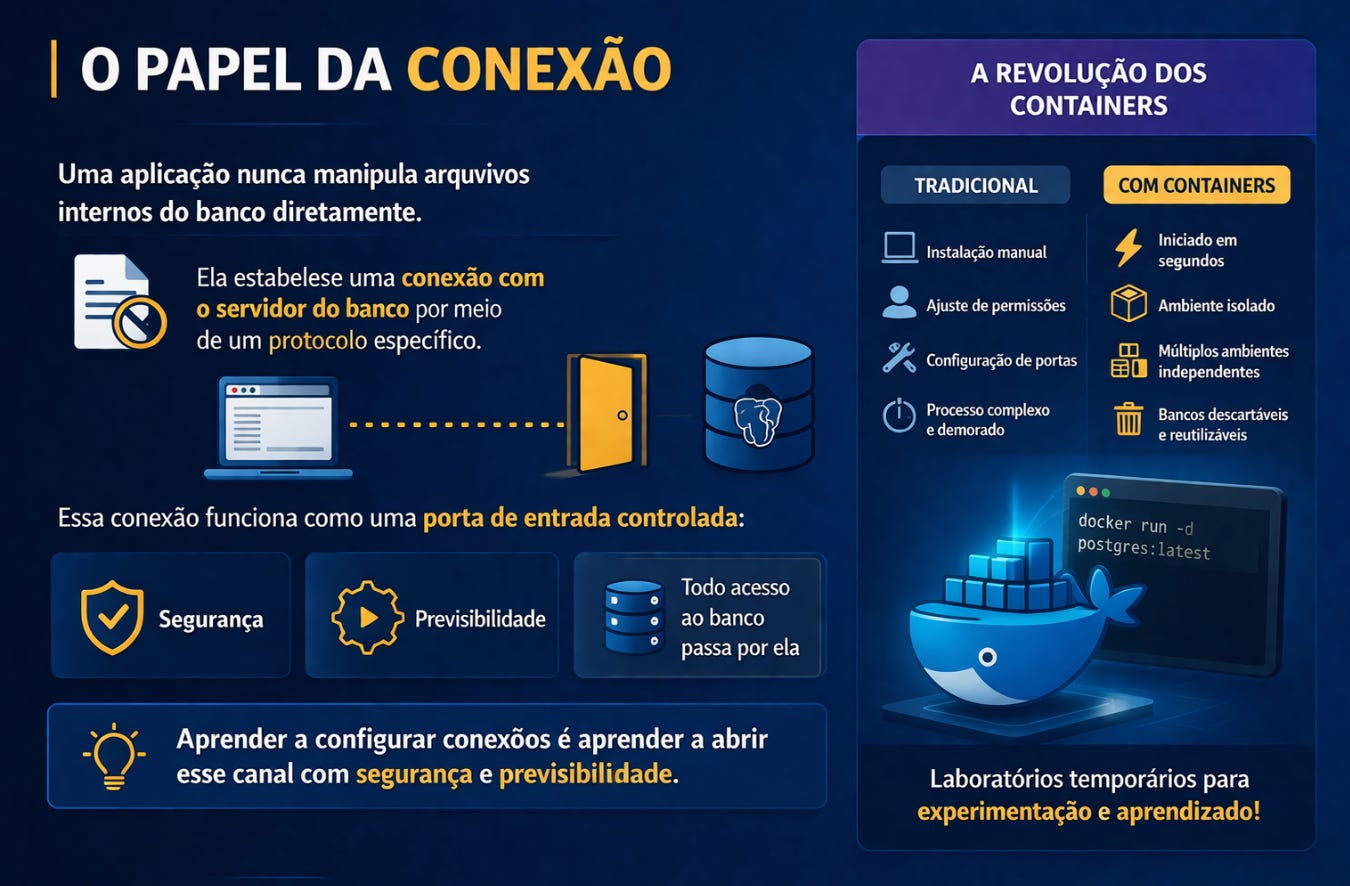
Outro aspecto importante dessa etapa é entender o papel da conexão. Uma aplicação nunca manipula arquivos internos do banco diretamente. Ela estabelece uma conexão com o servidor do banco por meio de um protocolo específico. Essa conexão funciona como uma porta de entrada controlada. Tudo o que acontece dentro do banco passa por ela. Aprender a configurar conexões significa aprender a abrir esse canal com segurança e previsibilidade.
Tradicionalmente, essa configuração envolvia instalar o banco manualmente na máquina local, ajustar permissões de usuário e configurar portas de comunicação. Hoje, o uso de containers transformou completamente esse processo. Um banco pode ser iniciado em poucos segundos dentro de um ambiente isolado, sem alterar o sistema principal do computador. Isso permite criar múltiplos ambientes independentes para testes, aprendizado ou desenvolvimento simultâneo. O estudante passa a trabalhar com bancos descartáveis, que podem ser criados e removidos conforme necessário, como pequenos laboratórios temporários de experimentação.
Esse tipo de ambiente aproxima o aprendizado da prática profissional contemporânea. Sistemas modernos raramente dependem de uma única instalação permanente. Eles operam em ambientes reproduzíveis, versionados e automatizados. Aprender a subir um banco com container é aprender a preparar infraestrutura leve para desenvolvimento real.
Outro ponto essencial dessa etapa é compreender a diferença entre ambiente local, ambiente de desenvolvimento e ambiente de produção. O banco instalado na máquina do estudante serve como espaço seguro para experimentação. Nele é possível testar estruturas, cometer erros e reconstruir tabelas sem impacto externo. Em ambientes de produção, cada alteração precisa ser cuidadosamente planejada, porque dados reais estão envolvidos. Entender essa distinção desde cedo evita uma confusão comum entre iniciantes: acreditar que manipular banco é apenas escrever comandos SQL.
Além disso, configurar um ambiente de banco significa aprender a observar o comportamento do sistema. Logs começam a aparecer, conexões podem falhar, permissões podem impedir acesso inesperadamente. Esses eventos não são obstáculos. São parte da linguagem operacional do banco. Quanto mais cedo o estudante se familiariza com eles, mais natural se torna trabalhar com sistemas reais.
Existe também uma transformação conceitual importante que acontece aqui. Até então, o banco era algo apresentado pelo professor ou pelo material didático. Depois da instalação, ele passa a ser responsabilidade do próprio estudante. Ele decide quando iniciar o serviço, quando parar, quando criar usuários e quando reorganizar estruturas. Esse pequeno deslocamento de controle marca o início de uma postura profissional diante da tecnologia.
Ao dominar a instalação e configuração de um ambiente de banco, o estudante deixa de depender de ambientes prontos e passa a construir os seus próprios. É como montar a primeira oficina pessoal antes de começar a trabalhar com ferramentas de verdade. A partir desse momento, cada consulta executada deixa de ser apenas um exercício e passa a acontecer dentro de um sistema que ele próprio colocou em funcionamento.
Linguagem SQL (aprofundamento)
É neste momento do curso que algo muda de natureza. Até aqui, o estudante observava o banco de dados como quem estuda o mapa de uma cidade antes de caminhar por ela. A linguagem SQL é o instante em que ele finalmente começa a percorrer as ruas. A partir daqui, o banco deixa de ser estrutura e passa a ser diálogo.
SQL não é apenas uma linguagem técnica. Ela é uma linguagem declarativa. Isso significa que, em vez de dizer ao sistema como executar cada passo de uma operação, o usuário descreve o que deseja obter. O banco decide o caminho. Essa característica altera profundamente a forma de pensar programação. Em muitas linguagens tradicionais, escrever código significa controlar a sequência de execução. Em SQL, significa formular perguntas com precisão lógica suficiente para que o sistema encontre respostas sozinho.
Quando alguém escreve uma consulta, está realizando uma tradução entre intenção humana e estrutura relacional. Esse processo exige clareza conceitual. Perguntas vagas produzem consultas confusas. Perguntas bem formuladas produzem resultados elegantes. Aprender SQL é aprender a perguntar melhor.
As primeiras interações com a linguagem costumam acontecer por meio de consultas de leitura. Nesse estágio, o estudante percebe que recuperar dados não é apenas visualizar tabelas. É selecionar subconjuntos específicos de informação dentro de universos potencialmente enormes. Uma consulta simples já exige decisões implícitas sobre quais colunas são relevantes, quais registros interessam e qual critério define pertencimento ao resultado. Mesmo operações aparentemente elementares carregam uma lógica de filtragem que se aproxima muito do raciocínio matemático.

À medida que o estudante avança, surge a capacidade de modificar dados. Inserir registros significa ampliar a memória do sistema. Atualizar registros significa alterar versões da realidade armazenada. Remover registros significa decidir que certas informações deixam de fazer parte da narrativa persistente do banco. Essas operações não são apenas comandos técnicos. Elas representam intervenções diretas na história do sistema. Por isso, a manipulação de dados exige responsabilidade estrutural.
Depois desse primeiro contato, aparece um dos elementos mais importantes da linguagem: a capacidade de combinar informações de tabelas diferentes. Bancos relacionais existem justamente para expressar relações. Consultar apenas uma tabela é como observar um objeto isolado. Relacionar tabelas é observar interações. Quando o estudante aprende a conectar entidades diferentes dentro de uma mesma consulta, ele começa a perceber que o banco não armazena apenas registros independentes, mas redes de significado.
Esse momento costuma provocar uma mudança silenciosa na compreensão do sistema. O banco deixa de parecer um conjunto de planilhas organizadas e passa a funcionar como uma estrutura coerente de relações interligadas. Consultas deixam de ser operações isoladas e passam a ser percursos entre entidades.
Em seguida, surge a capacidade de agrupar dados. Agrupar significa transformar registros individuais em padrões coletivos. Em vez de perguntar o que aconteceu com cada cliente, passamos a perguntar quantos clientes realizaram determinada ação. Em vez de observar pedidos separadamente, passamos a observar tendências. Nesse ponto, SQL começa a revelar seu poder analítico. O banco deixa de ser apenas um repositório operacional e passa a funcionar como instrumento de interpretação.
Subconsultas aparecem como uma forma de construir raciocínios em camadas. Elas permitem que uma pergunta seja respondida com base no resultado de outra pergunta anterior. Esse encadeamento cria consultas mais expressivas e aproxima SQL de uma linguagem de investigação lógica. O estudante passa a formular perguntas compostas, como quem constrói argumentos progressivos dentro de um texto.
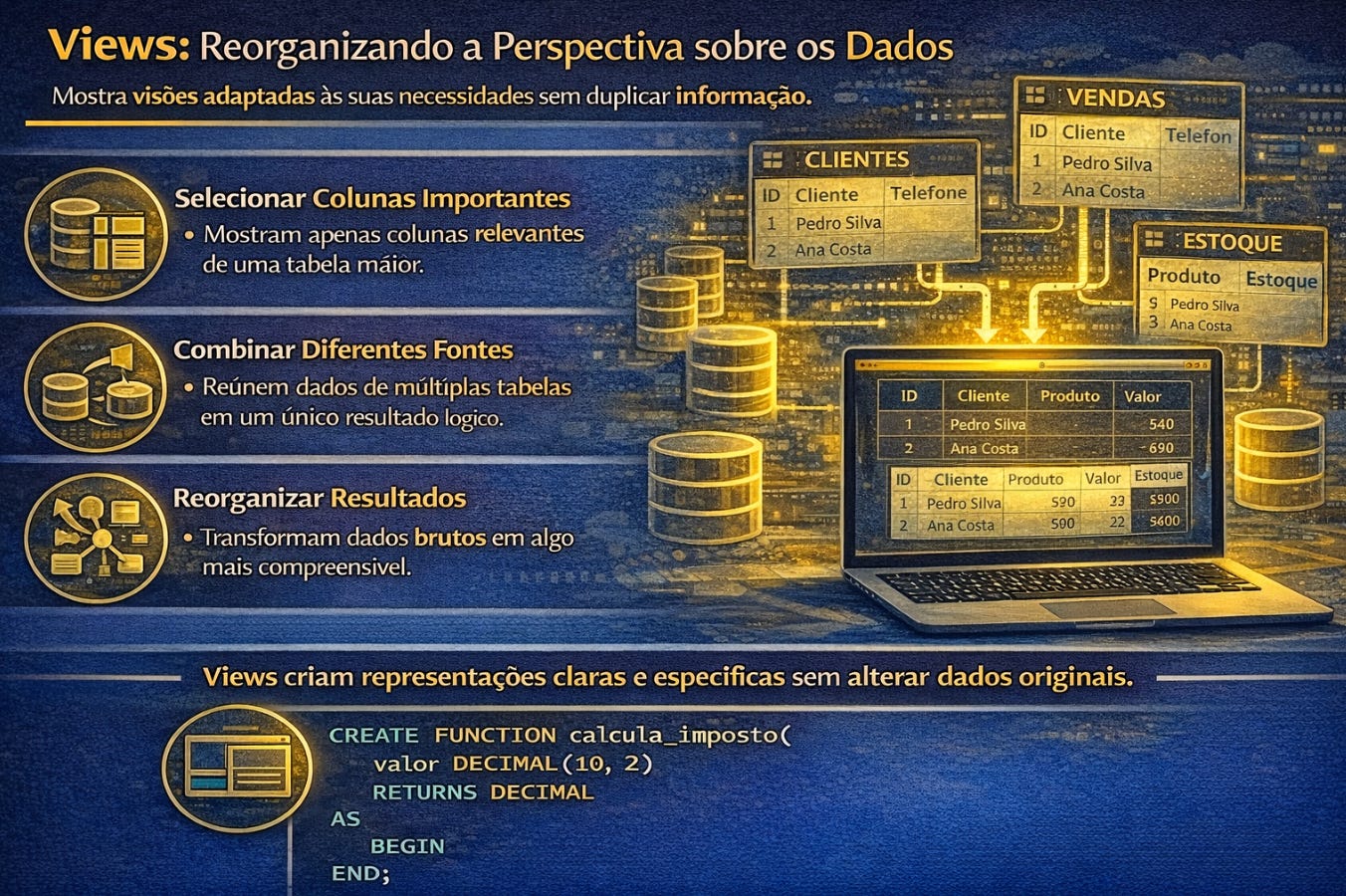
As visões, conhecidas como views, introduzem uma ideia ainda mais interessante. Elas permitem criar representações virtuais de dados sem duplicar armazenamento físico. É como construir janelas específicas dentro do banco, cada uma mostrando apenas aquilo que interessa para determinado contexto. Uma view não altera a realidade armazenada, mas altera a forma como essa realidade pode ser observada. Essa capacidade transforma SQL em uma ferramenta de organização semântica além de técnica.
As restrições estruturais, chamadas constraints, aparecem nesse momento como mecanismos de proteção da coerência interna do banco. Elas garantem que certos valores não possam assumir formas inválidas. Funcionam como regras silenciosas que preservam consistência ao longo do tempo. Um banco sem restrições é apenas um arquivo flexível. Um banco com restrições é um sistema confiável.

Quando o estudante avança para funções analíticas mais sofisticadas, algo novo acontece. Em vez de observar grupos separados, ele passa a observar padrões dentro de sequências. Essas funções permitem comparar registros com seus vizinhos, calcular rankings, detectar variações ao longo do tempo e identificar comportamentos progressivos. Nesse ponto, SQL começa a se aproximar da análise temporal e estatística.
As expressões conhecidas como CTEs, ou common table expressions, ampliam ainda mais a clareza estrutural das consultas. Elas permitem dividir perguntas complexas em etapas intermediárias organizadas. Em vez de escrever uma única consulta longa e difícil de interpretar, o estudante passa a construir pequenas camadas de raciocínio que se conectam progressivamente. O resultado é uma linguagem mais legível, mais modular e mais próxima de um pensamento estruturado.
Consultas analíticas representam o estágio em que SQL deixa definitivamente de ser apenas ferramenta de manipulação de dados e passa a ser instrumento de descoberta. Nesse nível, o banco não responde apenas perguntas diretas. Ele revela padrões escondidos, comportamentos recorrentes e tendências invisíveis em observações isoladas. O estudante começa a perceber que escrever consultas pode ser tão interpretativo quanto escrever um ensaio investigativo.

Por fim, surge a otimização. Esse é o momento em que a linguagem deixa de ser apenas correta e passa a ser eficiente. Uma consulta pode produzir o resultado esperado e ainda assim ser inadequada para grandes volumes de dados. Aprender otimização significa compreender como o banco interpreta cada comando internamente e ajustar a escrita da consulta para dialogar melhor com esse mecanismo invisível. É como aprender não apenas a falar com o sistema, mas a falar na velocidade dele.
Quando essa etapa é assimilada com profundidade, SQL deixa de parecer uma lista de comandos e passa a funcionar como uma linguagem de exploração. Cada consulta se torna uma pequena expedição dentro da memória estruturada do sistema. E quanto mais o estudante pratica, mais natural se torna atravessar esse território como quem já conhece seus atalhos secretos.
Programação em Banco de Dados
Existe um momento na trajetória de quem aprende SQL em que as consultas deixam de ser suficientes. Até aqui, o estudante aprende a perguntar ao banco, filtrar registros, relacionar tabelas e produzir análises. Mas ainda está operando de fora do sistema, como alguém que observa uma máquina através de um painel de controle. A programação em banco de dados marca a passagem para dentro da máquina. A partir desse ponto, não estamos apenas consultando dados. Estamos ensinando o próprio banco a executar lógica.

Programar dentro do banco significa transformar o banco em um agente ativo, capaz de reagir automaticamente a eventos, validar informações antes que sejam gravadas e executar rotinas complexas sem depender de aplicações externas. Em vez de o aplicativo controlar tudo, parte da inteligência passa a viver junto da estrutura onde os dados residem. Isso reduz latência, aumenta consistência e cria sistemas mais confiáveis.
Uma das primeiras formas dessa programação aparece nas procedures, também chamadas de stored procedures. Elas são blocos de código armazenados dentro do banco que podem ser executados sempre que necessário. Diferente de uma consulta comum, que existe apenas no momento em que é enviada pelo usuário, uma procedure permanece registrada no banco como parte permanente da sua lógica interna. Ela pode receber parâmetros, executar múltiplas operações e produzir resultados estruturados. Em sistemas reais, procedures frequentemente assumem tarefas críticas, como registrar transações financeiras, atualizar estoques ou consolidar dados operacionais.
O valor das procedures não está apenas na automação. Está na centralização da lógica. Quando regras importantes ficam espalhadas entre várias aplicações, o sistema se torna difícil de manter. Quando essas regras vivem dentro do banco, passam a existir em um único lugar confiável. Isso significa que qualquer aplicação conectada ao banco passa automaticamente a respeitar as mesmas regras sem precisar reimplementá-las.

As functions representam uma forma ainda mais refinada de programação interna. Elas se comportam como funções matemáticas aplicadas ao contexto do banco. Recebem valores de entrada e retornam um resultado específico. Diferente das procedures, que costumam executar operações completas, functions são usadas dentro de consultas. Elas ampliam a expressividade da linguagem SQL, permitindo encapsular cálculos complexos ou regras específicas de negócio dentro de chamadas reutilizáveis.
Esse tipo de estrutura aproxima SQL de linguagens tradicionais de programação. O banco deixa de ser apenas um executor de consultas e passa a oferecer um ambiente onde pequenas unidades de lógica podem ser organizadas e reutilizadas de forma elegante. Em ambientes analíticos modernos, funções personalizadas são frequentemente utilizadas para transformar dados antes de análises estatísticas ou agregações complexas.
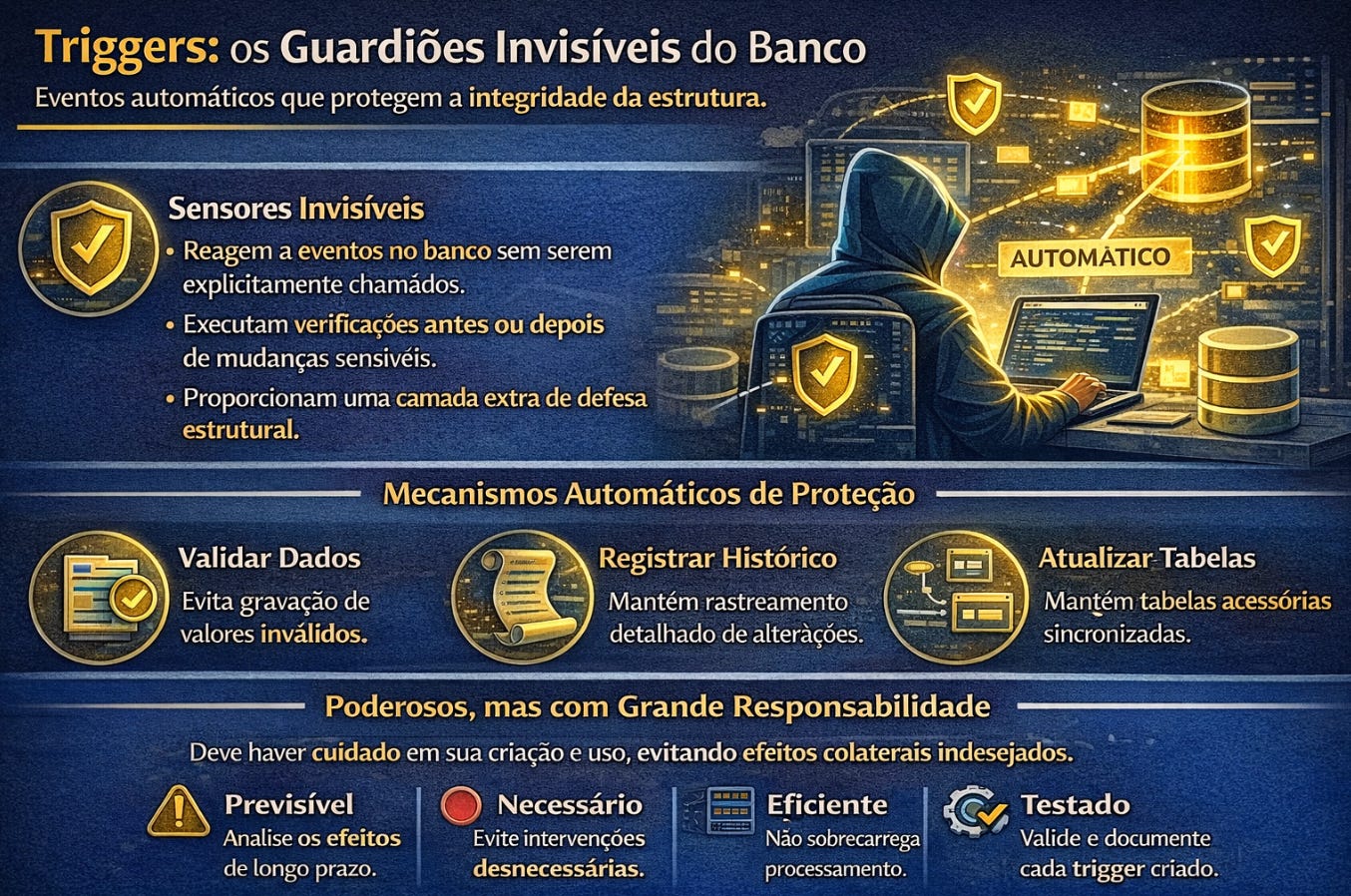
Entre todas as formas de programação dentro do banco, talvez nenhuma seja tão silenciosa quanto os triggers. Eles funcionam como sensores invisíveis instalados dentro da estrutura do sistema. Sempre que um evento específico acontece, como a inserção de um registro ou a alteração de um valor, o trigger é executado automaticamente. Nenhuma aplicação precisa chamá-lo explicitamente. Ele reage sozinho.
Isso permite construir mecanismos extremamente poderosos. Um trigger pode impedir que dados inválidos sejam gravados. Pode registrar histórico de alterações sem intervenção externa. Pode atualizar tabelas auxiliares automaticamente. Pode garantir consistência entre diferentes partes do banco. Em sistemas corporativos complexos, triggers funcionam como guardiões invisíveis da integridade estrutural.
No entanto, exatamente por operarem de forma automática, triggers exigem cuidado. Quando mal utilizados, podem tornar o comportamento do banco difícil de prever. Um desenvolvedor pode alterar um registro sem perceber que está acionando múltiplos processos internos invisíveis. Por isso, compreender triggers significa aprender não apenas a criá-los, mas a projetá-los com responsabilidade arquitetural.
Em bancos como Oracle e PostgreSQL, existe ainda o conceito de packages ou módulos organizacionais de código interno. Eles permitem agrupar funções relacionadas dentro de estruturas maiores e coerentes. Isso transforma o banco em um ambiente programável completo, onde lógica pode ser organizada de maneira semelhante a bibliotecas de software tradicionais. Em sistemas grandes, essa organização é essencial para manter clareza estrutural ao longo do tempo.
Na prática contemporânea, a programação dentro do banco também se conecta diretamente com pipelines de dados e ambientes analíticos distribuídos. Linguagens como PL/pgSQL no PostgreSQL ou T-SQL no SQL Server permitem escrever rotinas que executam transformações complexas diretamente sobre grandes volumes de dados sem precisar exportá-los para outras ferramentas. Isso reduz movimentação de dados e melhora desempenho geral do sistema.
Em plataformas cloud, essa ideia evoluiu ainda mais. Muitos bancos modernos permitem executar funções analíticas personalizadas próximas do armazenamento, reduzindo drasticamente o custo computacional de operações complexas. O banco deixa de ser apenas repositório e passa a atuar como motor de processamento.
Quando essa etapa é assimilada com profundidade, ocorre uma mudança importante na forma de pensar sistemas. O banco deixa de ser visto como um lugar onde dados ficam guardados esperando instruções externas. Ele passa a ser entendido como um componente ativo da arquitetura, capaz de executar lógica própria e participar diretamente da inteligência do sistema. Nesse momento, o estudante começa a perceber que programar banco de dados não é apenas escrever consultas melhores. É transformar o próprio banco em parte do programa.
Construção física do banco de dados
Existe um momento em que o modelo deixa de ser desenho e passa a ser território. Até aqui, a modelagem conceitual e lógica organizou entidades, relações e regras. A construção física é o instante em que essas decisões se tornam estruturas reais dentro do banco. É nesse ponto que o sistema começa, de fato, a existir.

Construir fisicamente um banco não significa apenas executar comandos de criação de tabelas. Significa transformar um entendimento abstrato do domínio em uma arquitetura persistente capaz de sustentar operações reais, crescimento futuro e consultas eficientes. A modelagem responde à pergunta “como o mundo deve ser representado”. A construção física responde “como essa representação será armazenada e acessada”.
A criação de tabelas representa o primeiro passo dessa materialização. Cada tabela passa a ocupar espaço no armazenamento do banco e começa a participar da organização interna das páginas de dados. Nesse momento, a escolha dos tipos de dados deixa de ser apenas uma formalidade sintática. Definir se um campo será inteiro, textual, temporal ou decimal influencia diretamente o desempenho das consultas, o consumo de memória e a capacidade de indexação futura. Um tipo de dado mal escolhido pode tornar uma estrutura inteira mais lenta sem que isso seja percebido imediatamente.

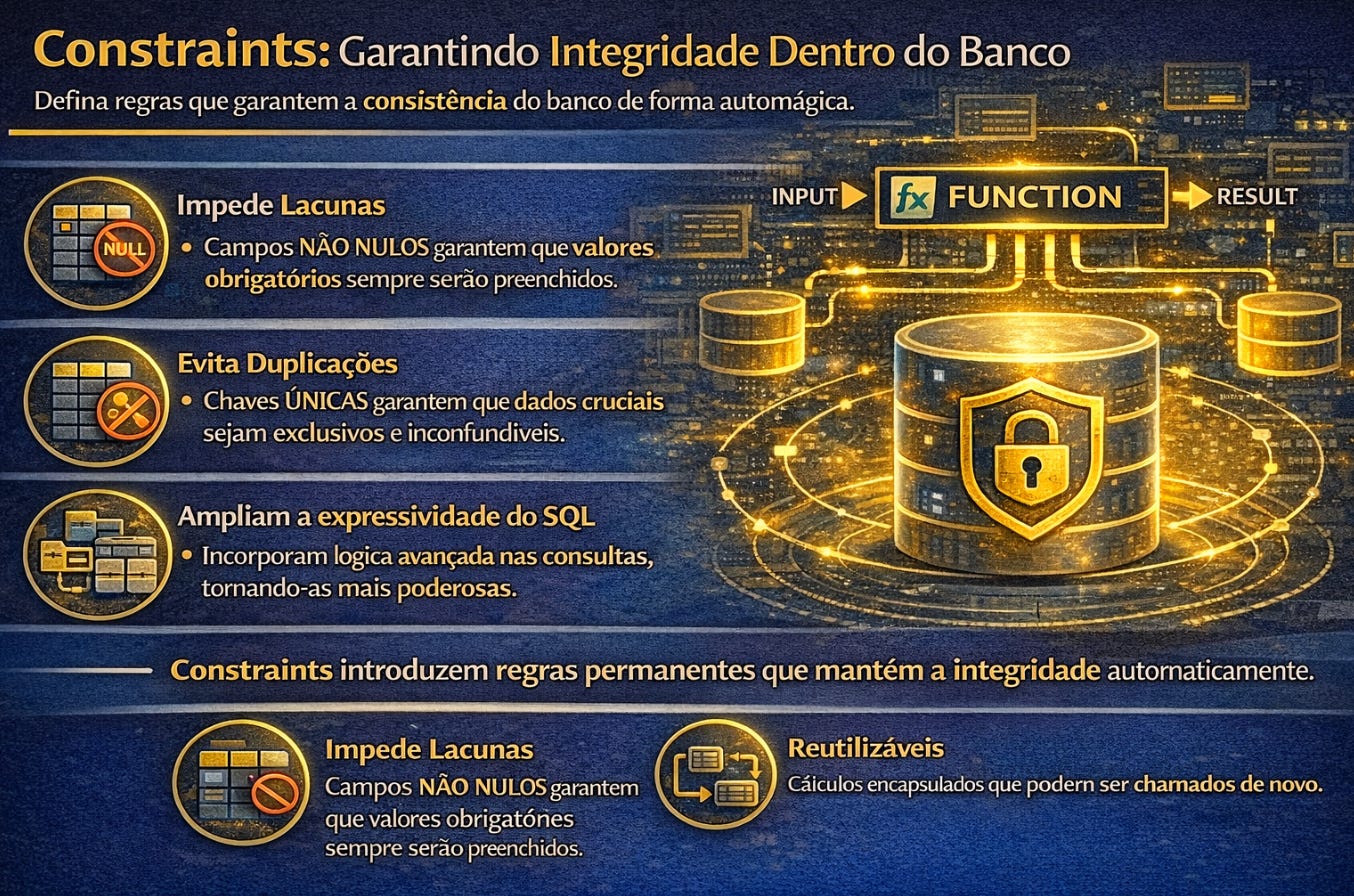
As restrições estruturais, conhecidas como constraints, introduzem regras permanentes dentro do banco. Elas garantem que os dados não apenas existam, mas permaneçam coerentes ao longo do tempo. Quando uma constraint define que determinado campo não pode ser nulo, ela impede lacunas de informação. Quando define unicidade, impede duplicações silenciosas. Quando estabelece relações entre tabelas, preserva a consistência narrativa do sistema. Essas regras não dependem da disciplina do programador. Elas passam a fazer parte do próprio comportamento do banco.
Os índices aparecem nesse estágio como instrumentos de navegação interna. Embora invisíveis para o usuário comum, eles reorganizam a forma como o banco percorre seus próprios registros. Sem índices, o sistema precisa examinar grandes volumes de dados para localizar um único valor específico. Com índices bem projetados, esse caminho se encurta drasticamente. Criar índices não é apenas acelerar consultas existentes. É antecipar quais caminhos de leitura o sistema utilizará com maior frequência no futuro.

Os schemas introduzem uma camada de organização estrutural que muitas vezes passa despercebida em projetos pequenos, mas se torna indispensável em ambientes maiores. Eles funcionam como espaços lógicos dentro do banco onde diferentes conjuntos de tabelas podem coexistir sem confusão. Em vez de um único repositório homogêneo, o banco passa a possuir territórios internos organizados por função, contexto ou responsabilidade. Essa divisão facilita manutenção, segurança e evolução da estrutura ao longo do tempo.
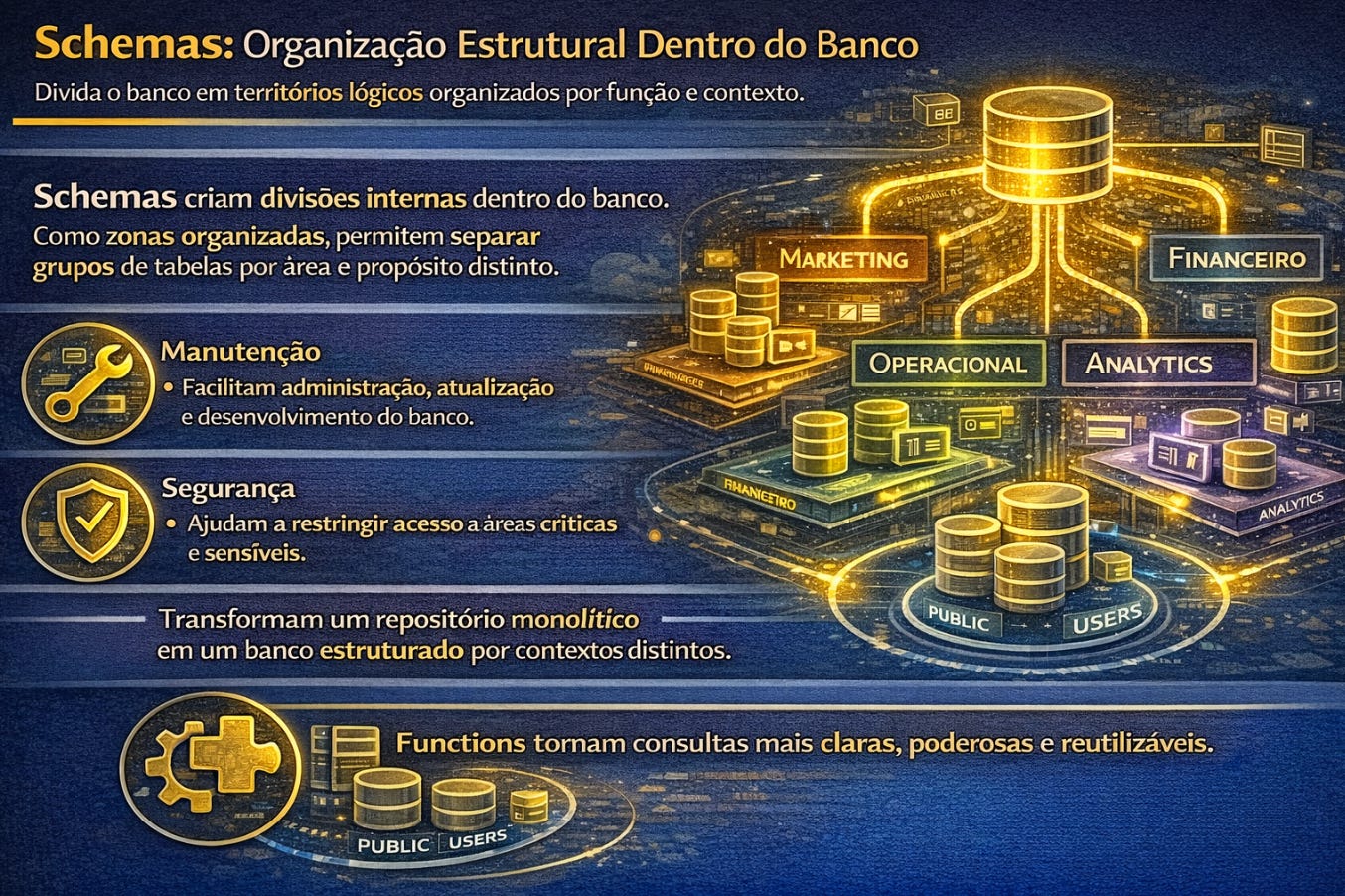
As views surgem como uma forma elegante de reorganizar a forma como os dados são apresentados sem alterar o armazenamento físico. Elas permitem construir representações específicas para diferentes necessidades sem duplicar informação. Uma view pode mostrar apenas parte das colunas de uma tabela, combinar dados de múltiplas fontes ou reorganizar resultados de forma mais compreensível para determinado contexto de uso. Isso transforma o banco em um sistema capaz de oferecer múltiplas perspectivas sobre o mesmo conjunto de dados.
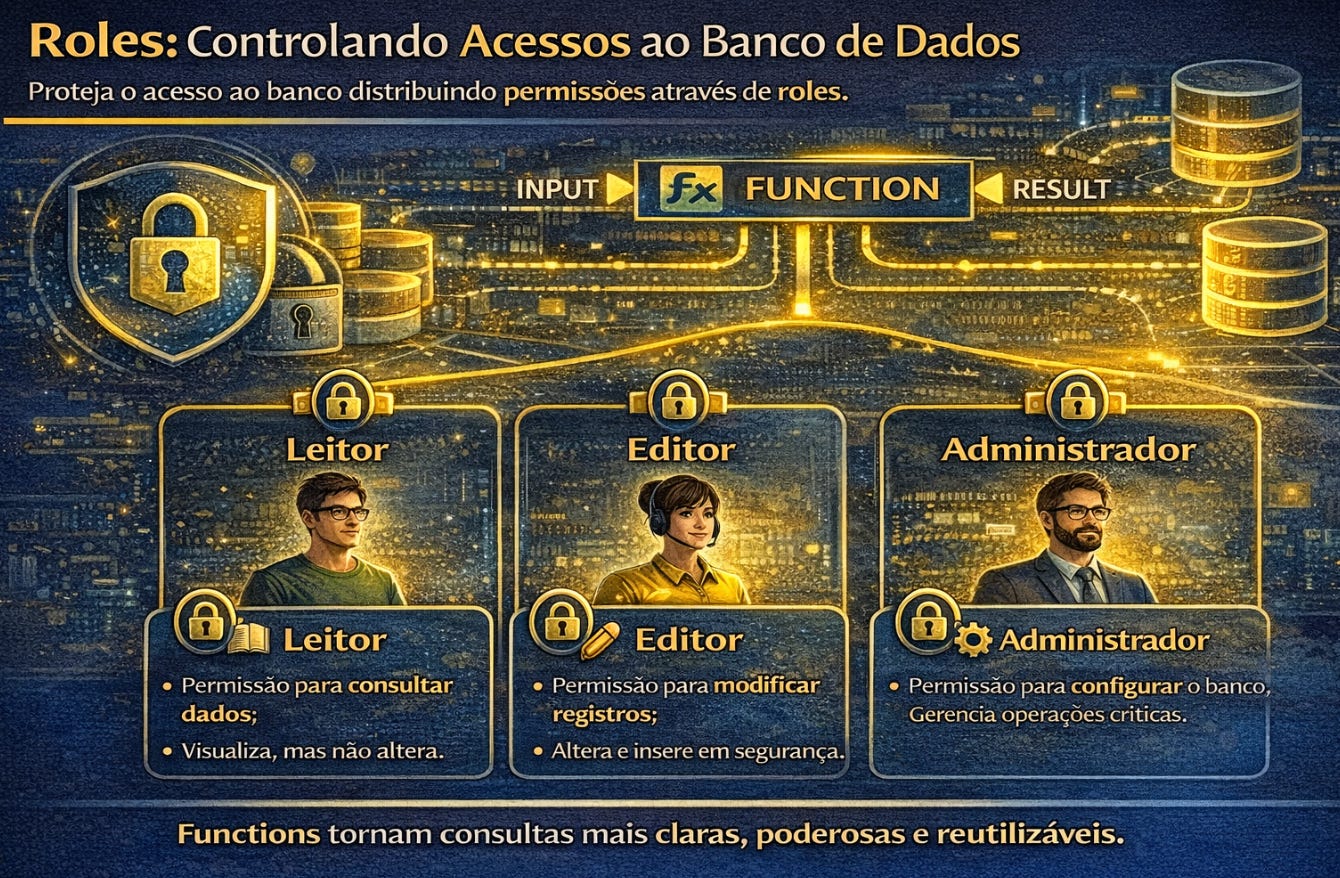
A definição de roles representa a introdução consciente de controle de acesso dentro da estrutura física. Um banco não é apenas um repositório técnico. Ele é um ambiente compartilhado por diferentes aplicações e usuários com responsabilidades distintas. Definir roles significa estabelecer quem pode ler, quem pode alterar e quem pode administrar determinadas partes do sistema. Essa separação protege dados sensíveis e evita alterações acidentais em estruturas críticas.
Quando essas decisões são implementadas em conjunto, algo importante acontece. O banco deixa de ser um modelo hipotético e passa a funcionar como uma infraestrutura concreta capaz de sustentar operações reais. A transição entre teoria e produção acontece silenciosamente nesse momento. O estudante percebe que cada escolha feita durante a modelagem agora possui consequências técnicas observáveis. Tipos de dados influenciam desempenho. índices influenciam velocidade. constraints influenciam consistência. schemas influenciam organização. roles influenciam segurança.
Construir fisicamente um banco é, portanto, mais do que executar comandos de criação. É transformar decisões conceituais em comportamento estrutural permanente. É o instante em que o projeto deixa de ser intenção e passa a ser sistema.
Documentação de ambiente de banco de dados
Existe uma dimensão do trabalho com banco de dados que quase nunca aparece nos primeiros contatos com SQL, mas que determina se um sistema será sustentável ao longo do tempo ou se se tornará lentamente incompreensível até para quem o construiu. Essa dimensão é a documentação do ambiente. Documentar um banco de dados não é uma tarefa burocrática. É um exercício de preservação da memória estrutural do sistema.
Todo banco de dados começa pequeno, claro e inteligível. No início, cada tabela tem um propósito evidente, cada coluna parece autoexplicativa e cada relação é fácil de reconstruir mentalmente. Mas à medida que o sistema cresce, novas tabelas surgem, campos mudam de significado, integrações são adicionadas e regras de negócio evoluem. Sem documentação, esse crescimento transforma o banco em um território opaco. O problema não é apenas técnico. É cognitivo. As pessoas deixam de compreender o sistema que utilizam.

O dicionário de dados surge como uma das primeiras ferramentas para evitar esse processo. Ele não é apenas uma lista de tabelas. É uma descrição do significado de cada elemento armazenado. Quando uma coluna chamada status aparece em uma tabela, por exemplo, ela pode representar situações completamente diferentes dependendo do contexto. Pode indicar o estado de um pedido, o progresso de um atendimento ou a situação de um pagamento. O dicionário de dados registra esse significado e impede que interpretações divergentes surjam com o tempo.

Descrever tabelas também significa registrar o papel que cada entidade desempenha dentro da arquitetura geral do sistema. Uma tabela pode armazenar dados operacionais, históricos, intermediários ou derivados. Sem essa distinção explícita, alguém pode utilizar uma tabela de apoio como se fosse uma fonte oficial de informação, gerando inconsistências analíticas difíceis de detectar depois. A documentação torna visível aquilo que o modelo estrutural sozinho não consegue explicar.
Outra camada essencial da documentação envolve o controle de versões. Bancos de dados não permanecem estáticos. Estruturas mudam conforme novas funcionalidades são implementadas. Campos são adicionados, índices são alterados, relações são reorganizadas. Sem registro dessas mudanças, torna-se impossível reconstruir a trajetória do sistema ou compreender por que determinada decisão foi tomada. O controle de versões permite acompanhar a evolução do banco como se fosse uma narrativa técnica contínua.
Diagramas entidade-relacionamento também desempenham um papel importante nesse processo. Embora sejam frequentemente associados apenas à fase inicial de modelagem, eles continuam úteis durante toda a vida do sistema. Um diagrama atualizado permite que alguém visualize rapidamente como as tabelas se conectam e quais caminhos de consulta são possíveis. Em ambientes grandes, esse tipo de representação funciona como um mapa indispensável para navegação estrutural.

Registrar alterações feitas no ambiente completa esse conjunto de práticas. Muitas decisões técnicas parecem evidentes no momento em que são tomadas, mas se tornam difíceis de justificar meses depois. Quando mudanças são documentadas junto com seus motivos, o banco passa a preservar não apenas sua estrutura atual, mas também a lógica que orientou sua construção. Isso reduz conflitos interpretativos e facilita manutenção futura.
Nos ambientes contemporâneos, a documentação deixou de existir apenas como arquivos isolados e passou a fazer parte do próprio fluxo de desenvolvimento. Ferramentas baseadas em Markdown permitem registrar estruturas diretamente junto ao código. Plataformas como dbt docs transformam modelos de dados em documentação navegável automaticamente. Catálogos de dados organizam tabelas e métricas dentro de estruturas pesquisáveis. Espaços colaborativos como Notion ou Confluence funcionam como centros vivos de conhecimento compartilhado sobre o sistema.
Quando essa etapa é levada a sério, o banco de dados deixa de ser apenas uma infraestrutura técnica e passa a ser um sistema compreensível por diferentes pessoas ao longo do tempo. Documentar um ambiente é garantir que ele continue legível mesmo depois que seus criadores já não estejam mais presentes. É uma forma silenciosa de engenharia que não altera diretamente a execução das consultas, mas determina profundamente a longevidade e a confiabilidade do sistema.
Conectividade entre bancos de dados
Existe uma transformação silenciosa que acontece quando deixamos de enxergar um banco de dados como um sistema isolado e passamos a percebê-lo como parte de uma rede de sistemas. A conectividade entre bancos nasce exatamente dessa mudança de perspectiva. Ela não trata apenas de como acessar dados, mas de como permitir que diferentes ambientes conversem entre si sem perder consistência, significado ou confiabilidade.
Durante muito tempo, trabalhar com banco de dados significava interagir com uma única instância central. A aplicação consultava aquele banco, gravava informações nele e todo o fluxo acontecia dentro de um único território controlado. Hoje, essa lógica quase nunca existe sozinha. Sistemas modernos distribuem dados entre múltiplos serviços, plataformas analíticas, APIs externas e pipelines automatizados. O banco deixou de ser destino final da informação. Ele passou a ser um ponto de passagem dentro de um ecossistema maior.
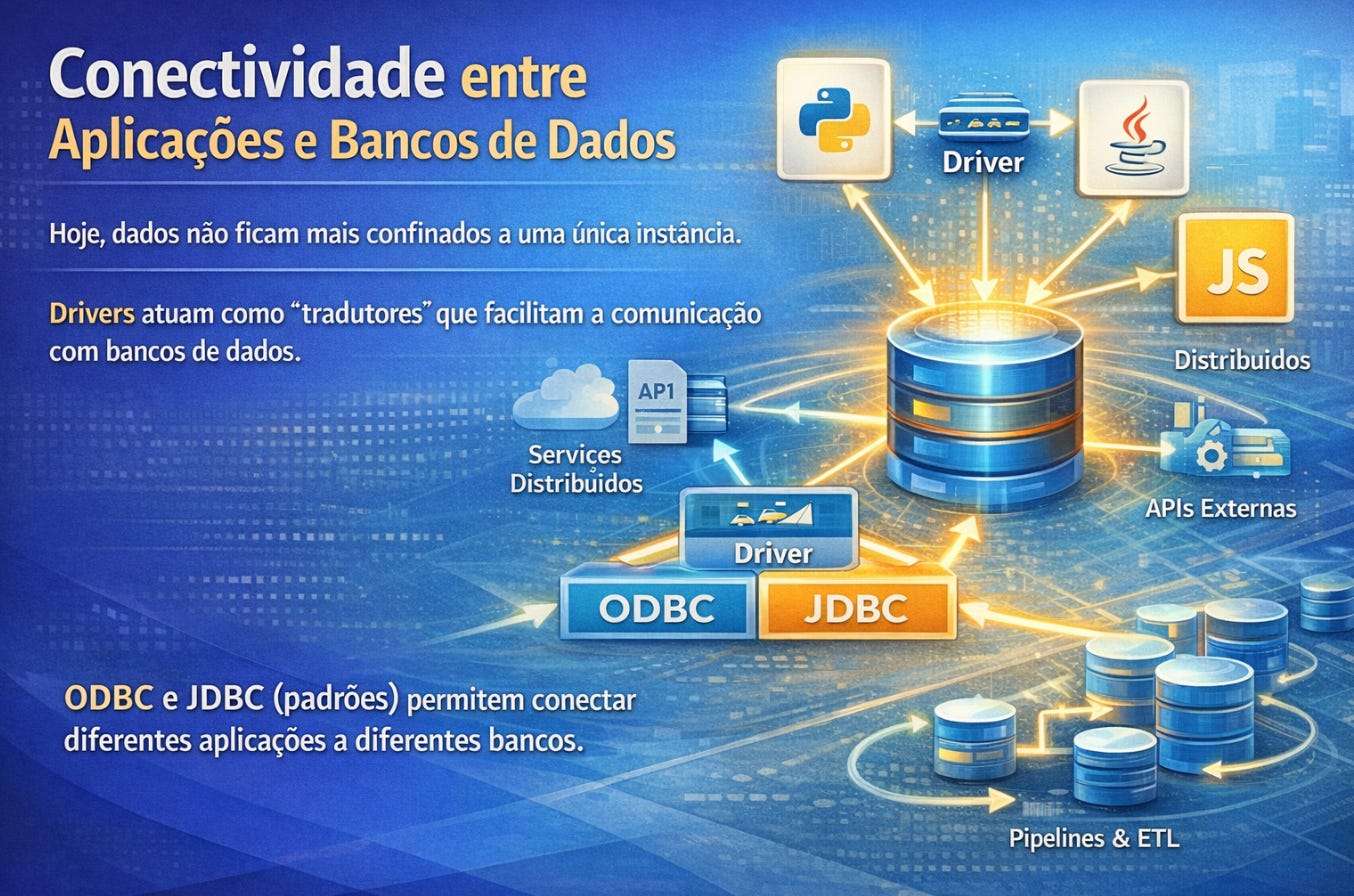
A conectividade começa com algo aparentemente simples: estabelecer comunicação entre aplicação e banco. Essa comunicação acontece por meio de drivers, que funcionam como tradutores entre linguagens diferentes. Um programa escrito em Python, Java ou JavaScript não fala diretamente com o banco. Ele utiliza um driver capaz de converter instruções internas da linguagem em comandos compreensíveis pelo SGBD. Essa tradução é invisível para o usuário final, mas absolutamente essencial para o funcionamento do sistema.
Protocolos como ODBC e JDBC surgiram justamente para padronizar essa conversa. Eles criaram uma espécie de idioma intermediário que permite que diferentes aplicações acessem diferentes bancos sem precisar aprender um novo mecanismo de conexão a cada tecnologia utilizada. Esse tipo de padronização foi decisivo para a expansão dos sistemas corporativos distribuídos, porque reduziu o custo de integração entre ferramentas heterogêneas.
Com o crescimento das arquiteturas baseadas em serviços independentes, a conectividade deixou de acontecer apenas entre aplicação e banco. Passou a acontecer entre bancos diferentes. Um sistema operacional pode armazenar dados transacionais em PostgreSQL enquanto envia cópias estruturadas para um warehouse analítico em Snowflake ou BigQuery. Nesse cenário, o banco deixa de ser um destino único e passa a participar de fluxos contínuos de transformação e redistribuição de dados.
Esse fluxo é o que dá origem aos pipelines de dados. Um pipeline não é apenas um transporte automático de registros entre sistemas. Ele é uma sequência organizada de etapas onde dados são extraídos, transformados e carregados em novos ambientes com finalidades específicas. Informações operacionais podem ser reorganizadas para análise estatística, monitoramento de métricas ou treinamento de modelos preditivos. A conectividade deixa então de ser apenas técnica e passa a ser interpretativa. Os dados mudam de contexto conforme atravessam o sistema.
Ferramentas como Airflow surgem nesse cenário como orquestradoras desses movimentos. Elas não armazenam dados diretamente. Organizam o tempo e a ordem em que diferentes operações acontecem. Funcionam como uma espécie de maestro invisível que coordena quando extrair informações, quando transformá-las e quando disponibilizá-las para análise. Essa coordenação garante que ambientes complexos continuem sincronizados mesmo quando envolvem múltiplos bancos e múltiplas fontes externas.
O dbt representa outro passo nessa evolução. Em vez de apenas mover dados entre sistemas, ele organiza transformações diretamente dentro do ambiente analítico. Isso significa que a lógica de interpretação dos dados passa a ser versionada, documentada e reproduzível. A conectividade deixa de ser apenas transporte e passa a ser modelagem contínua. O banco analítico deixa de ser um repositório passivo e se transforma em um espaço ativo de construção semântica.
Ferramentas como Spark ampliam ainda mais essa capacidade ao permitir processamento distribuído em larga escala. Nesse contexto, dados não precisam mais ser analisados dentro de um único servidor. Eles podem ser fragmentados em múltiplos nós de processamento e reorganizados paralelamente. A conectividade passa a envolver não apenas bancos diferentes, mas também múltiplos ambientes computacionais operando simultaneamente sobre o mesmo conjunto de informações.
Kafka introduz uma dimensão adicional nesse cenário ao tratar dados como fluxos contínuos em vez de registros estáticos armazenados em tabelas. Nesse modelo, eventos são transmitidos em tempo real entre sistemas que precisam reagir imediatamente a mudanças. A conectividade deixa de ser baseada apenas em consultas e passa a ser baseada em transmissão de acontecimentos. O banco deixa de ser apenas memória. Passa a participar de um sistema nervoso distribuído que conecta serviços em movimento constante.
Quando essa etapa é compreendida com profundidade, o estudante percebe que trabalhar com banco de dados não significa apenas organizar tabelas corretamente. Significa entender como a informação circula entre diferentes partes de um sistema maior. O banco deixa de ser um ponto fixo e passa a funcionar como uma estação dentro de uma rede viva de dados em trânsito. É nesse momento que surge uma percepção importante: dados não existem apenas para serem armazenados. Eles existem para viajar.
Segurança em banco de dados
A segurança em banco de dados começa antes mesmo de qualquer consulta ser escrita. Ela nasce no momento em que entendemos que dados não são apenas registros técnicos, mas representações de pessoas, decisões, contratos, comportamentos e histórias. Proteger um banco não significa apenas impedir invasões externas. Significa garantir que a informação continue íntegra, confidencial e confiável ao longo de todo o seu ciclo de vida.
Durante muito tempo, a segurança era tratada como uma camada adicional aplicada depois que o sistema já estava funcionando. Hoje, ela faz parte da própria arquitetura do banco. Cada tabela criada, cada usuário configurado e cada conexão estabelecida já participa de uma estratégia de proteção estrutural. Segurança deixou de ser um mecanismo defensivo e passou a ser um componente essencial do desenho do sistema.
O controle de acesso representa o primeiro nível dessa estrutura. Nem toda pessoa que utiliza um banco precisa enxergar tudo o que ele contém. Um sistema financeiro, por exemplo, pode permitir que um operador visualize pedidos, mas não valores sensíveis de pagamento. Um analista pode consultar métricas agregadas sem acesso a dados pessoais. Esse tipo de separação não é apenas uma prática organizacional. É uma forma de reduzir riscos antes mesmo que eles apareçam. Quando o banco sabe exatamente quem pode acessar cada parte de sua estrutura, ele transforma permissões em fronteiras invisíveis de proteção.

As roles surgem como uma maneira elegante de organizar essas fronteiras. Em vez de conceder permissões individuais para cada usuário, criam-se perfis de acesso que representam funções dentro do sistema. Uma role pode representar um analista, um administrador ou um serviço automatizado. Ao associar usuários a essas funções, o banco passa a refletir a própria organização do ambiente onde opera. Isso torna a segurança mais previsível, mais escalável e mais fácil de auditar.
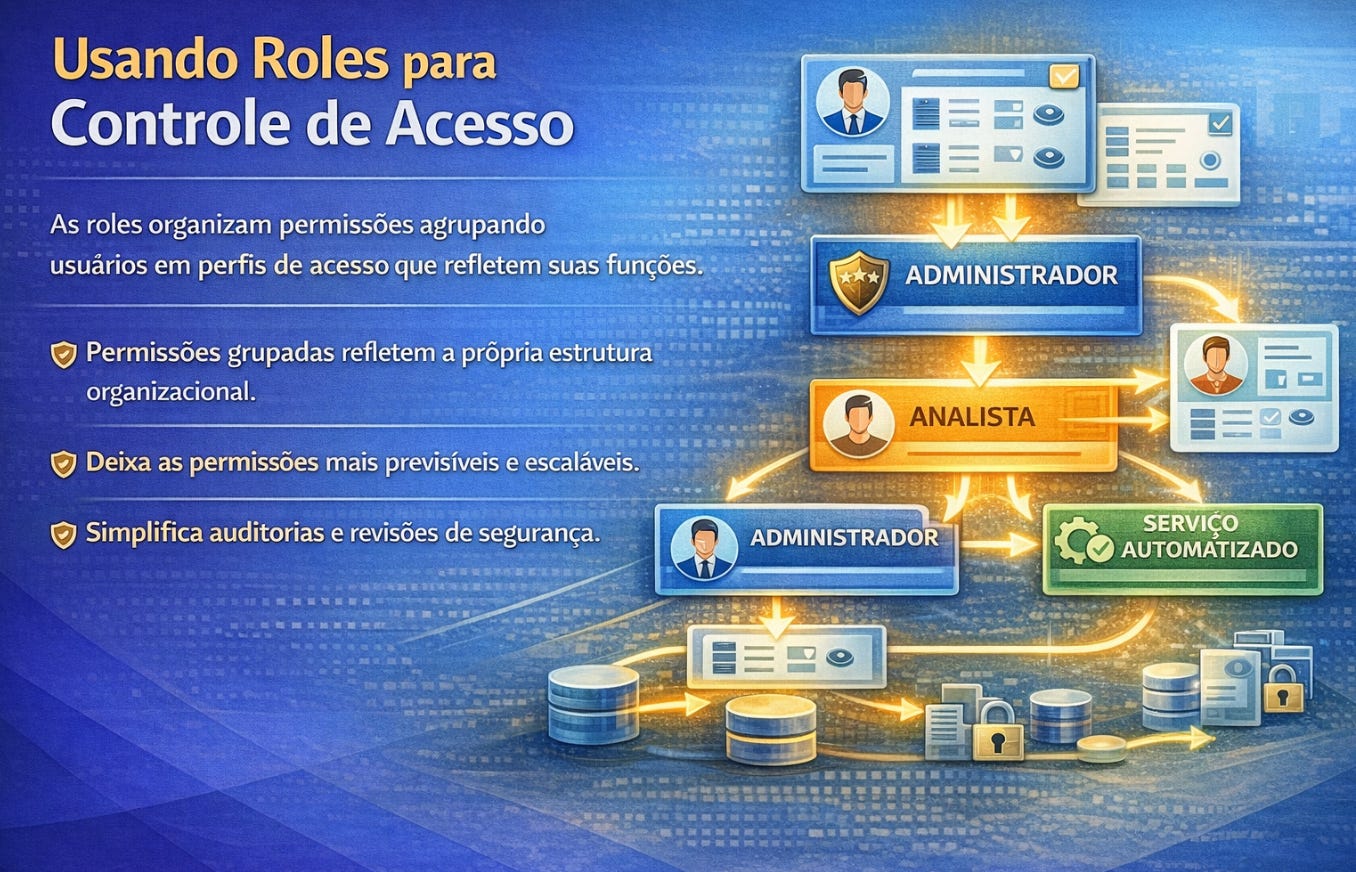
As permissões aprofundam esse mecanismo ao definir exatamente o que cada role pode fazer. Ler não é o mesmo que alterar. Alterar não é o mesmo que excluir. Administrar não é o mesmo que executar consultas. Cada uma dessas ações representa um nível diferente de responsabilidade sobre os dados. Quando permissões são bem definidas, o banco deixa de depender do cuidado individual de cada usuário e passa a proteger sua própria integridade automaticamente.

A criptografia introduz uma camada ainda mais profunda de proteção. Ela garante que, mesmo que alguém consiga acessar fisicamente os dados armazenados, não conseguirá interpretá-los sem a chave correta. Esse mecanismo pode atuar tanto durante o armazenamento quanto durante a transmissão das informações. Em ambientes distribuídos, onde dados atravessam redes constantemente, essa proteção se torna essencial para evitar interceptações silenciosas.
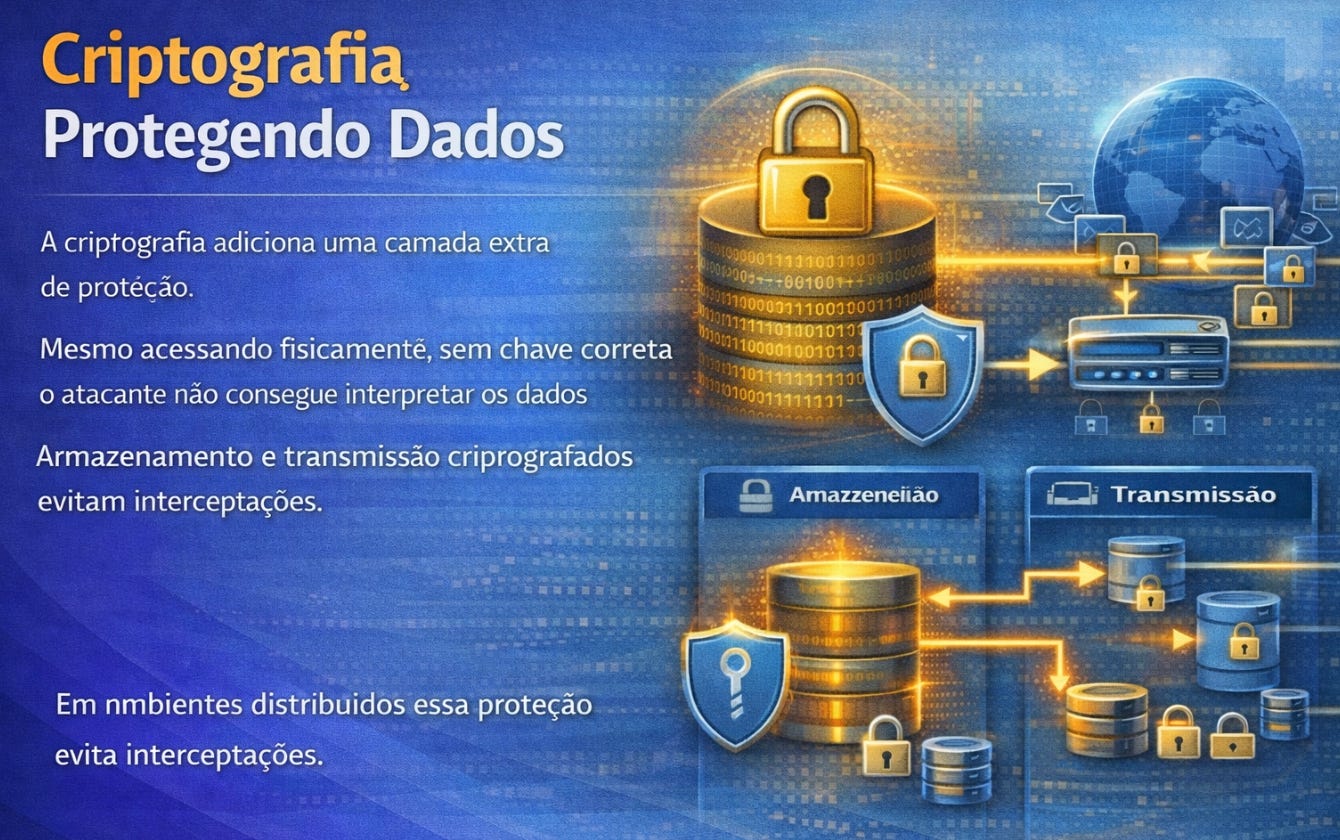
A auditoria completa esse conjunto inicial ao registrar tudo o que acontece dentro do banco. Cada alteração, cada tentativa de acesso e cada operação sensível pode ser rastreada. Isso transforma o banco em um ambiente observável, onde comportamentos inesperados deixam rastros detectáveis. Auditoria não impede problemas diretamente, mas torna possível compreender quando algo aconteceu, como aconteceu e quem esteve envolvido. Essa capacidade é fundamental em sistemas críticos.

Com o avanço das legislações de proteção de dados, a segurança passou a incluir também responsabilidades jurídicas. Regulamentos como a LGPD estabeleceram que dados pessoais precisam ser tratados com transparência, finalidade definida e proteção adequada. Isso significa que o banco não pode armazenar informações indefinidamente sem justificativa nem permitir acesso indiscriminado a dados sensíveis. A estrutura técnica precisa refletir essas exigências legais. Segurança deixou de ser apenas uma questão de infraestrutura e passou a ser também uma questão de governança.
O masking surge como uma resposta prática a esse desafio. Ele permite ocultar parcialmente informações sensíveis sem removê-las do banco. Um número de documento pode aparecer truncado, um e-mail pode ser parcialmente mascarado e um endereço pode ser simplificado para análises estatísticas. Dessa forma, o sistema continua útil para trabalho analítico sem expor dados pessoais desnecessariamente.
Row-level security representa um avanço ainda mais refinado nesse controle. Em vez de decidir apenas quem pode acessar uma tabela inteira, o banco passa a decidir quem pode acessar cada linha individualmente. Isso permite construir sistemas onde diferentes usuários consultam a mesma tabela, mas enxergam apenas os registros que lhes dizem respeito. O banco deixa de proteger apenas estruturas e passa a proteger contextos específicos de informação.
Nos ambientes modernos baseados em nuvem, a segurança se expande novamente. Bancos deixam de existir como instâncias isoladas e passam a fazer parte de plataformas integradas com serviços de autenticação centralizados. O modelo conhecido como IAM permite controlar identidades, permissões e acessos em múltiplos serviços simultaneamente. Nesse cenário, a segurança não é aplicada apenas dentro do banco. Ela envolve toda a infraestrutura que permite que o banco exista.
Quando essa etapa é compreendida com profundidade, algo importante muda na forma de enxergar sistemas de dados. Segurança deixa de parecer um conjunto de restrições que dificultam o trabalho e passa a ser entendida como a estrutura que permite que o trabalho aconteça com confiança. Um banco seguro não é apenas protegido contra ataques externos. Ele é um ambiente onde cada informação sabe exatamente quem pode vê-la, por que pode vê-la e até quando pode permanecer ali.
Fundamentos: aprender a pensar antes de consultar
A primeira fase do curso não começa com comandos SQL e isso não é um atraso. É uma escolha pedagógica deliberada. Antes de escrever consultas, é necessário desenvolver uma forma específica de enxergar informação. Essa fase existe para construir exatamente essa forma de pensamento.
Quando alguém inicia o estudo de banco de dados diretamente pela linguagem SQL, costuma aprender a executar operações sem compreender plenamente o sistema onde essas operações acontecem. A consulta funciona, o resultado aparece, mas a lógica estrutural permanece invisível. O objetivo desta fase é evitar esse tipo de aprendizado superficial. Em vez de começar perguntando ao banco, começamos entendendo como o banco organiza o mundo.
Arquitetura de banco de dados é o primeiro contato com essa mudança de perspectiva. Aqui o estudante aprende que dados não estão simplesmente armazenados em tabelas como células de uma planilha. Eles fazem parte de um sistema que controla acesso simultâneo, mantém consistência interna, organiza memória e responde a consultas com base em estratégias próprias de execução. O banco deixa de ser um arquivo sofisticado e passa a ser compreendido como uma infraestrutura ativa de informação.
Em seguida entra a modelagem de dados, que talvez seja o ponto mais decisivo dessa etapa. Modelar dados significa aprender a representar a realidade com precisão estrutural. Não se trata apenas de criar tabelas. Trata-se de decidir o que existe dentro do sistema, o que não existe, quais entidades possuem identidade própria e quais dependem de outras para fazer sentido. Um pedido pode existir sem pagamento confirmado, mas não pode existir sem cliente associado. Um produto pode existir sem estoque disponível, mas não sem definição de categoria. Essas decisões parecem simples no início, mas formam a base de toda a coerência futura do banco.
Ao aprender modelagem, o estudante começa a perceber que bancos de dados não armazenam apenas registros. Eles armazenam relações entre eventos. Cada tabela representa um fragmento de uma narrativa maior. Quando essas relações são bem definidas, o sistema se torna previsível. Quando são mal definidas, surgem inconsistências que nenhuma consulta consegue corrigir depois.
Os conceitos estruturais completam essa primeira fase ao introduzir ideias como identidade, dependência, integridade e normalização. Esses conceitos funcionam como princípios invisíveis que orientam decisões técnicas futuras. Eles explicam por que certas estruturas são estáveis ao longo do tempo enquanto outras se tornam difíceis de manter. Explicam por que duplicar informação pode parecer conveniente no início, mas se transforma em problema depois. Explicam por que relações bem definidas tornam consultas mais simples mesmo em sistemas grandes.
O objetivo final dessa fase é construir uma mudança silenciosa no modo de raciocinar. Em vez de pensar em dados como valores isolados, o estudante passa a pensar em estruturas conectadas. Em vez de enxergar tabelas como listas, passa a enxergá-las como representações formais de entidades reais. Em vez de escrever consultas para resolver perguntas imediatas, passa a antecipar como essas perguntas poderiam evoluir no futuro.
Pensar como engenheiro de dados antes de escrever SQL significa exatamente isso. Significa compreender que cada consulta é apenas a superfície visível de uma arquitetura muito maior. Quando essa base está bem construída, aprender SQL deixa de ser um exercício de memorização e passa a ser uma extensão natural do raciocínio estrutural já desenvolvido.
Estrutura física: quando o banco deixa de ser ideia e passa a ser máquina
Depois de compreender arquitetura e modelagem, acontece uma transição importante no aprendizado. Até aqui, o banco de dados existia como representação conceitual do mundo. Sabíamos quais entidades existiam, como se relacionavam e por que precisavam existir daquela forma. A segunda fase introduz algo diferente: agora começamos a entender como essa estrutura realmente vive dentro do sistema.
Essa mudança parece sutil, mas altera completamente a forma como alguém passa a escrever SQL, criar tabelas e interpretar desempenho.
Instalar um banco de dados é o primeiro contato com essa realidade concreta. Nesse momento, o estudante percebe que o banco não é apenas um conjunto de comandos que aparecem em uma interface gráfica. Ele é um serviço que precisa ser iniciado, configurado, conectado e mantido em funcionamento. Ele ocupa memória, escreve arquivos em disco, registra transações e administra múltiplos acessos simultaneamente. A partir da instalação, o banco deixa de ser abstração acadêmica e passa a ser infraestrutura ativa.

Essa percepção muda a relação com o sistema. Em vez de depender de ambientes prontos, o estudante passa a construir o próprio ambiente de trabalho. Isso significa compreender onde os dados são armazenados fisicamente, como o banco escuta conexões externas e como ele organiza internamente suas estruturas de persistência. É como montar o próprio laboratório antes de começar os experimentos.
A criação de tabelas marca o segundo momento dessa fase, mas agora com um significado diferente do que tinha na modelagem. Antes, tabelas eram representações conceituais de entidades. Aqui, elas passam a ser estruturas reais que ocupam espaço físico dentro do banco. Cada coluna criada influencia como os dados serão armazenados. Cada tipo de dado escolhido altera consumo de memória, velocidade de leitura e comportamento de indexação. Uma tabela deixa de ser apenas desenho lógico e passa a ser um objeto material dentro do sistema.
Esse detalhe costuma passar despercebido no início, mas tem consequências profundas. Um campo definido como texto quando deveria ser numérico pode comprometer operações futuras. Um campo temporal mal estruturado pode dificultar análises históricas. Pequenas decisões nessa etapa produzem efeitos que aparecem meses depois, quando o banco cresce.
A organização interna do banco completa essa fase ao revelar como ele realmente trabalha por trás das consultas. Quando escrevemos um comando SQL, imaginamos que o banco percorre linhas organizadas em tabelas. Na prática, ele percorre páginas de armazenamento distribuídas em estruturas internas otimizadas para leitura e escrita. O banco não “vê” tabelas como nós vemos. Ele vê blocos de dados organizados estrategicamente para responder perguntas com eficiência.
Entender isso transforma a forma de pensar desempenho. Uma consulta lenta raramente é lenta por causa da linguagem. Ela é lenta porque percorre caminhos físicos longos dentro do armazenamento. Quando aprendemos como o banco organiza páginas, buffers e índices, começamos a prever o comportamento das consultas antes mesmo de executá-las. É como aprender a ouvir o funcionamento interno de um motor antes de dirigir o carro.
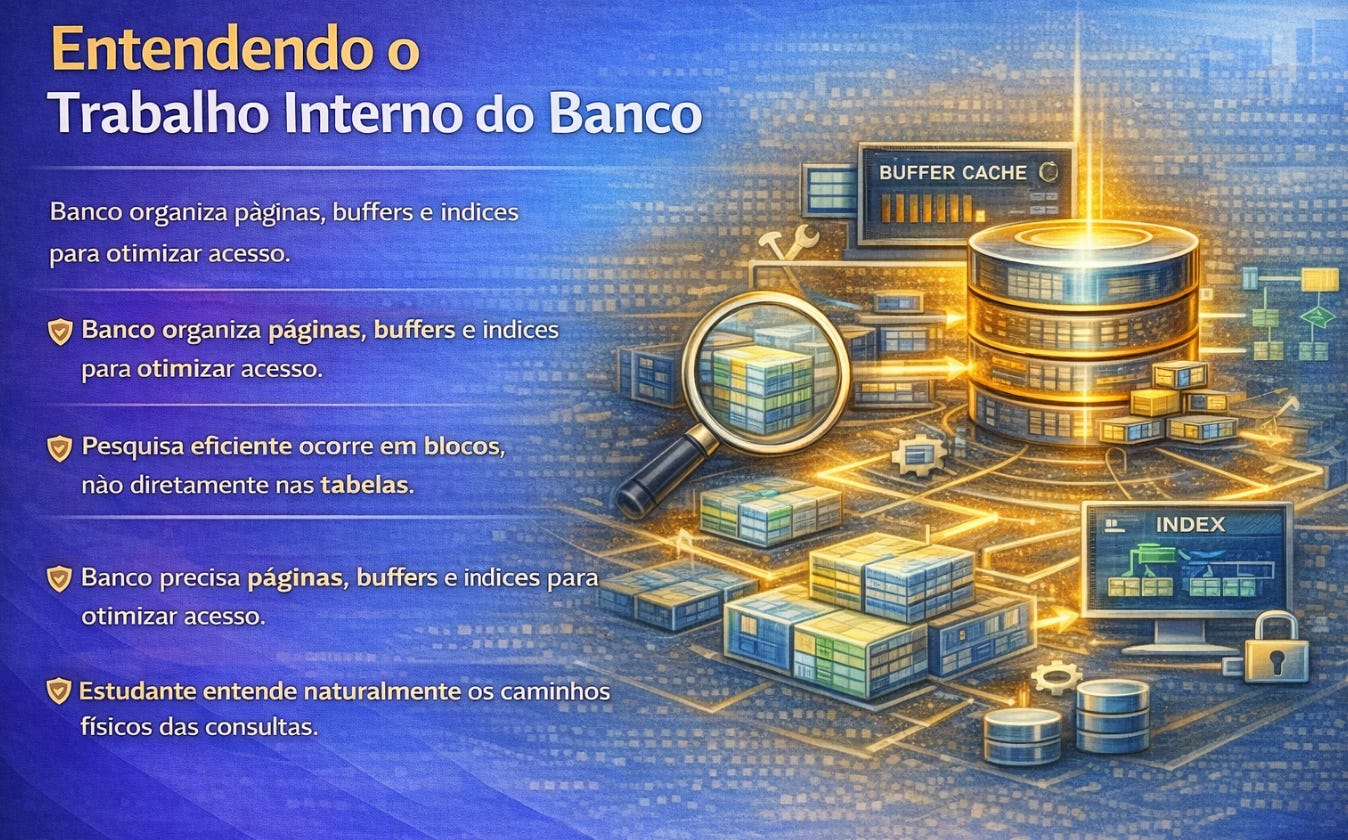
Essa fase também introduz a ideia de que o banco possui memória de curto prazo e memória de longo prazo. Parte dos dados permanece temporariamente em áreas rápidas de acesso para acelerar consultas frequentes. Outra parte permanece armazenada em disco aguardando leitura sob demanda. Essa diferença explica por que consultas repetidas podem se tornar mais rápidas com o tempo e por que certas operações pesadas parecem “aquecer” o sistema antes de estabilizar.
Compreender a estrutura física do banco é, portanto, compreender que dados não existem apenas como valores organizados logicamente. Eles existem como objetos distribuídos em um espaço técnico real, governado por regras de armazenamento, leitura e otimização. Quando essa percepção se consolida, o estudante deixa de escrever comandos apenas para obter resultados e passa a escrever comandos que dialogam diretamente com o funcionamento interno do sistema.
É nesse momento que o banco deixa de parecer uma caixa preta misteriosa e passa a se revelar como uma máquina inteligível, previsível e, aos poucos, familiar.
Programação em banco: quando o banco deixa de armazenar e passa a agir
Existe um ponto no aprendizado em que o banco de dados deixa de ser apenas um lugar onde informações ficam guardadas esperando consultas externas. A partir da programação em banco, ele passa a participar ativamente da execução do sistema. Essa mudança é profunda. O banco deixa de ser passivo e passa a se comportar como um componente lógico da aplicação.
Até aqui, o fluxo era relativamente simples. A aplicação enviava comandos, o banco respondia com dados. Toda a inteligência estava fora dele. A programação interna altera essa relação. Parte das regras de funcionamento do sistema passa a existir dentro do próprio banco, próxima da informação que precisa ser protegida, transformada ou validada.
Esse deslocamento de lógica não acontece por acaso. Ele resolve problemas estruturais que aparecem quando sistemas crescem. Quando regras importantes ficam espalhadas entre diferentes aplicações, cada parte do sistema passa a interpretar os dados de maneira ligeiramente diferente. Pequenas divergências se acumulam e, com o tempo, surgem inconsistências difíceis de rastrear. Ao centralizar essas regras dentro do banco, cria-se um ponto único de verdade operacional.
As procedures representam uma das formas mais diretas dessa centralização. Elas funcionam como rotinas armazenadas permanentemente dentro do banco e podem executar sequências completas de operações. Em vez de enviar várias instruções separadas a partir da aplicação, é possível chamar uma única procedure que já conhece todos os passos necessários. Isso reduz tráfego entre aplicação e banco, melhora desempenho e garante que operações complexas sejam executadas sempre da mesma forma.
Em sistemas financeiros, por exemplo, registrar uma transação não significa apenas inserir um valor em uma tabela. Pode envolver atualização de saldo, registro histórico, validação de limites e geração de auditoria. Quando essas etapas vivem dentro de uma procedure, tornam-se indivisíveis. Ou todas acontecem corretamente, ou nenhuma acontece. Esse comportamento protege a integridade do sistema de forma automática.
As funções introduzem uma camada diferente de expressividade. Elas permitem encapsular cálculos e regras específicas que podem ser reutilizados dentro de consultas. Uma função pode calcular uma métrica, transformar um valor ou interpretar uma informação de acordo com critérios definidos previamente. Isso evita repetição de lógica em múltiplas consultas e torna o banco capaz de oferecer respostas mais sofisticadas diretamente.
Essa capacidade aproxima o banco de uma linguagem de programação estruturada. Consultas deixam de ser apenas operações de leitura e passam a incorporar pequenas unidades de raciocínio reutilizável. Em ambientes analíticos, funções são frequentemente utilizadas para preparar dados antes de agregações ou comparações temporais mais complexas.
Os triggers introduzem talvez a forma mais silenciosa e poderosa de programação interna. Eles reagem automaticamente a eventos que acontecem dentro do banco. Sempre que um registro é inserido, alterado ou removido, o trigger pode executar uma ação adicional sem que ninguém precise chamá-lo explicitamente. Isso transforma o banco em um sistema capaz de observar a si mesmo.
Essa observação automática permite implementar mecanismos importantes de integridade. Um trigger pode registrar histórico de alterações, impedir modificações indevidas ou sincronizar informações entre tabelas relacionadas. Em vez de depender da disciplina de quem escreve consultas, o próprio banco passa a garantir que determinadas regras sejam respeitadas.
Ao mesmo tempo, triggers exigem maturidade técnica. Como operam de forma invisível para quem executa a consulta, podem introduzir comportamentos inesperados se forem mal projetados. Por isso, aprender triggers significa também aprender responsabilidade arquitetural. Eles devem reforçar a previsibilidade do sistema, não obscurecê-la.
Em bancos mais completos, como PostgreSQL e Oracle, a programação interna pode ser organizada em estruturas maiores, onde procedures e funções passam a formar conjuntos coerentes de lógica reutilizável. Isso transforma o banco em um ambiente programável completo, capaz de sustentar parte significativa da inteligência operacional de aplicações complexas.
Nos ambientes modernos baseados em cloud e análise de dados em larga escala, essa lógica evoluiu ainda mais. Hoje é possível executar transformações sofisticadas diretamente dentro do banco analítico, reduzindo movimentação de dados entre ferramentas diferentes. Em vez de exportar dados para outro sistema para processamento, o processamento acontece próximo do armazenamento. Isso aumenta eficiência e reduz custos computacionais.
Quando essa fase é assimilada com profundidade, ocorre uma mudança importante na forma de enxergar o papel do banco dentro de uma arquitetura. Ele deixa de ser apenas um repositório consultável e passa a ser um participante ativo do comportamento do sistema. Nesse momento, programar banco de dados deixa de significar apenas escrever consultas melhores. Passa a significar ensinar o próprio banco a trabalhar junto com você.
Integração com outras disciplinas técnicas: aprender banco de dados é aprender a pensar sistemas
Um dos equívocos mais comuns no início do estudo de banco de dados é imaginar que SQL é uma habilidade isolada, quase como aprender a usar uma ferramenta específica dentro de um conjunto maior de tecnologias. Na prática, banco de dados funciona como uma espécie de eixo estrutural silencioso que atravessa praticamente todas as áreas da computação aplicada. Ele não é uma disciplina periférica. É uma linguagem de organização do mundo digital.
Quando alguém aprende banco de dados com profundidade, começa a perceber que essa aprendizagem altera a forma como problemas são interpretados antes mesmo de qualquer solução ser escrita. Não se trata apenas de armazenar informações corretamente. Trata-se de entender como informações se relacionam, como evoluem ao longo do tempo e como podem ser recuperadas de forma confiável para sustentar decisões técnicas e analíticas.
A relação com algoritmos aparece primeiro porque ambos compartilham um mesmo compromisso com estrutura. Um algoritmo descreve uma sequência de passos para resolver um problema. Um modelo de dados descreve a estrutura onde esse problema existe. Quando essas duas dimensões não conversam, surgem sistemas que funcionam apenas superficialmente. Um algoritmo eficiente aplicado sobre uma estrutura mal modelada continua produzindo resultados frágeis. Por outro lado, uma estrutura bem organizada permite que algoritmos simples resolvam problemas complexos com clareza.
A lógica de programação aprofunda essa conexão ao introduzir a ideia de fluxo de execução. Em linguagens tradicionais, o programador controla explicitamente cada passo que o sistema deve seguir. Em SQL, esse controle é substituído por uma lógica declarativa. Em vez de definir o caminho, define-se o objetivo. Essa diferença não é apenas sintática. Ela altera a maneira de pensar soluções. O estudante passa a perceber que nem todo problema precisa ser resolvido com sequências de instruções detalhadas. Alguns podem ser resolvidos descrevendo relações entre conjuntos de dados.
A engenharia de software amplia ainda mais essa integração. Sistemas reais não existem como programas isolados executando tarefas simples. Eles são compostos por múltiplos componentes que precisam compartilhar informações de maneira consistente. O banco de dados atua como ponto de estabilidade dentro dessa arquitetura. Ele preserva estados, garante integridade entre módulos diferentes e permite que funcionalidades evoluam sem comprometer estruturas existentes. Quando o banco é bem projetado, o sistema inteiro se torna mais previsível. Quando é mal projetado, cada nova funcionalidade aumenta a fragilidade do conjunto.
A conexão com backend surge de forma natural porque praticamente toda aplicação que mantém estado depende de um banco de dados. Um serviço pode receber requisições, processar dados e retornar respostas, mas precisa de algum lugar onde essas informações continuem existindo depois que a execução termina. O banco ocupa esse papel. Mais do que isso, ele influencia diretamente o desenho das APIs, o formato das respostas e a organização dos fluxos de informação dentro da aplicação. Um desenvolvedor backend que compreende modelagem de dados escreve sistemas mais estáveis porque antecipa problemas antes que eles apareçam na execução.
Analytics representa talvez a integração mais visível atualmente. Toda análise depende da qualidade da estrutura onde os dados foram armazenados. Métricas confiáveis não nascem apenas de boas consultas. Elas dependem de decisões feitas muito antes, na modelagem inicial do banco. Quando eventos são registrados corretamente, análises se tornam naturais. Quando são registrados de forma inconsistente, nenhuma ferramenta consegue reconstruir significado depois. Aprender banco de dados é aprender a preparar o terreno onde a análise futura será possível.
Por isso, o objetivo deste curso não é ensinar apenas comandos SQL. O objetivo é desenvolver uma forma estruturada de raciocinar sobre informação. Quem aprende a pensar dessa maneira passa a enxergar sistemas como redes de relações organizadas, e não como sequências isoladas de instruções. Esse tipo de visão acompanha toda a trajetória técnica, independentemente da área escolhida depois. SQL pode até ser a primeira ferramenta visível desse processo, mas o que realmente se aprende aqui é uma maneira diferente de organizar o pensamento sobre dados.
Ensino aplicado ao mercado de trabalho: formar alguém que sabe operar sistemas reais, não apenas responder provas
Existe uma diferença profunda entre aprender banco de dados para passar em uma disciplina e aprender banco de dados para trabalhar com sistemas reais. À primeira vista, essa diferença pode parecer apenas uma questão de motivação individual, mas na prática ela altera completamente a forma como o conhecimento é construído.
Quando o objetivo principal é concluir uma disciplina, o estudo tende a se organizar em torno de conteúdos isolados. O estudante aprende comandos específicos, memoriza estruturas de consulta e reproduz exercícios que já possuem solução conhecida. Nesse cenário, o banco de dados aparece como um conjunto de técnicas que precisam ser dominadas temporariamente para atingir um resultado imediato: a aprovação. O conhecimento existe, mas permanece compartimentado. Ele não se conecta naturalmente com situações imprevisíveis, que são justamente aquelas que aparecem no trabalho cotidiano.
Já a formação orientada ao mercado parte de um princípio diferente. Em vez de tratar SQL como uma linguagem a ser decorada, ela trata dados como uma infraestrutura viva que sustenta decisões reais dentro de sistemas complexos. O foco deixa de ser executar comandos corretamente e passa a ser compreender por que determinadas estruturas existem, como elas evoluem ao longo do tempo e quais consequências produzem quando são mal projetadas.
Isso muda inclusive a natureza dos exercícios. Em um modelo tradicional, o estudante recebe uma tabela pronta e precisa escrever uma consulta específica sobre ela. Em um modelo profissional, ele precisa decidir primeiro se aquela tabela deveria existir daquela forma. Precisa avaliar se a modelagem permite responder perguntas futuras. Precisa antecipar quais relações ainda não estão explícitas e podem se tornar necessárias depois. A consulta deixa de ser o objetivo final e passa a ser apenas uma etapa dentro de um raciocínio maior.
Essa diferença também aparece na forma como erros são interpretados. Em um ambiente orientado apenas à aprovação, o erro é algo a ser evitado rapidamente para não comprometer a nota. Em um ambiente orientado à prática profissional, o erro é um instrumento de aprendizado estrutural. Ele revela limites da modelagem, inconsistências de relacionamento ou escolhas inadequadas de tipos de dados. Corrigir o erro passa a significar compreender melhor o sistema, não apenas ajustar a sintaxe.
Outro aspecto importante dessa abordagem é a relação com o tempo. O conhecimento voltado para provas costuma ser consumido rapidamente e descartado com a mesma rapidez. Já o conhecimento voltado para o trabalho precisa permanecer utilizável por anos. Isso exige que conceitos sejam compreendidos em profundidade suficiente para serem adaptados a contextos diferentes, tecnologias diferentes e volumes de dados diferentes. O estudante deixa de aprender apenas “como fazer” e passa a entender “por que fazer dessa maneira”.
Nesse contexto, o objetivo do curso não é apenas ensinar comandos SQL corretos. É desenvolver uma forma de raciocinar sobre dados que continue válida mesmo quando as ferramentas mudarem. Linguagens evoluem, plataformas desaparecem e arquiteturas se transformam, mas a capacidade de modelar informação com coerência permanece. É essa capacidade que define alguém preparado para atuar profissionalmente.
Quando se diz que o produto final do curso é o aluno qualificado, não apenas aprovado, isso significa que o aprendizado foi pensado para sobreviver fora da sala de aula. Significa que cada conceito apresentado foi escolhido não apenas por fazer parte de um programa curricular, mas por representar uma competência que aparece repetidamente em situações reais de desenvolvimento, análise ou engenharia de dados. O resultado esperado não é apenas alguém que sabe responder perguntas sobre bancos de dados, mas alguém que consegue construir estruturas confiáveis dentro deles.
Rotina de estudo esperada: como o conhecimento em banco de dados realmente se consolida
Aprender banco de dados não acontece por exposição ocasional ao conteúdo. Diferente de disciplinas mais conceituais, onde é possível compreender ideias lendo e refletindo, o domínio de dados exige repetição ativa. Existe uma transformação cognitiva que só ocorre quando o estudante começa a interagir continuamente com estruturas reais. É nesse contato frequente que consultas deixam de parecer fórmulas estranhas e passam a se tornar extensões naturais do raciocínio.
A prática semanal não é apenas uma recomendação organizacional. Ela é a forma mais eficiente de treinar a percepção estrutural necessária para trabalhar com dados. Cada vez que alguém escreve uma consulta, interpreta um resultado inesperado ou reorganiza uma tabela mal modelada, está desenvolvendo uma intuição silenciosa sobre como a informação se comporta dentro do banco. Essa intuição não surge de leitura passiva. Ela surge da convivência constante com o sistema.
Resolver exercícios desempenha um papel importante nesse processo porque expõe o estudante a diferentes formas de formular perguntas sobre os mesmos dados. No início, consultas parecem sempre exigir esforço consciente. Com o tempo, padrões começam a aparecer. Certas estruturas deixam de ser novidade e passam a funcionar como ferramentas familiares. O cérebro aprende a reconhecer relações entre tabelas antes mesmo de terminar de ler o problema. Esse tipo de reconhecimento é um sinal claro de que a aprendizagem deixou de ser superficial.
Modelar sistemas amplia ainda mais esse processo porque desloca o foco da resposta para a estrutura da pergunta. Em vez de apenas consultar dados existentes, o estudante passa a decidir quais dados deveriam existir. Essa mudança altera profundamente a forma de pensar. Modelar significa antecipar necessidades futuras, prever relações entre entidades e evitar inconsistências antes que apareçam. É uma atividade de arquitetura, não apenas de execução técnica.
Escrever queries reais representa outro ponto essencial dessa rotina. Exercícios didáticos são importantes, mas dados reais raramente se comportam como exemplos organizados em apostilas. Eles possuem lacunas, redundâncias, exceções e inconsistências inesperadas. Trabalhar com dados desse tipo ensina algo que nenhum exercício isolado consegue transmitir: a capacidade de adaptar consultas a contextos imperfeitos. Esse tipo de experiência aproxima o aprendizado do ambiente profissional.
Participar de projetos completa essa formação porque introduz uma dimensão coletiva ao trabalho com dados. Em sistemas reais, o banco não pertence a uma única pessoa. Ele faz parte de uma arquitetura compartilhada, onde decisões precisam considerar impacto sobre outras partes do sistema. Projetos ensinam a negociar estruturas, documentar escolhas e pensar na evolução do banco ao longo do tempo. Essa experiência transforma conhecimento técnico em prática de engenharia.
Quando essas atividades acontecem de forma contínua, algo importante se desenvolve gradualmente. O estudante deixa de enxergar SQL como uma sequência de comandos que precisam ser lembrados e passa a utilizá-lo como uma linguagem natural de investigação. Consultas deixam de ser tentativas e passam a ser hipóteses estruturadas sobre como a informação está organizada. É nesse momento que a repetição deixa de parecer exercício e passa a funcionar como construção de autonomia.
Atividades práticas fora da aula: onde o aprendizado deixa de ser guiado e passa a ser construído
Uma parte importante da formação em banco de dados acontece fora do momento formal de aula porque é nesse espaço que o estudante deixa de seguir instruções e começa a tomar decisões próprias sobre como investigar, estruturar e interpretar dados. Esse tipo de atividade não funciona como complemento opcional do conteúdo. Ele funciona como continuação natural do processo de aprendizagem.
Quando alguém trabalha apenas com exemplos apresentados em aula, existe sempre uma estrutura invisível sustentando o exercício. O problema já foi selecionado, os dados já foram organizados e o caminho da solução já foi antecipado pelo professor. Fora desse ambiente, o estudante passa a lidar com uma realidade diferente. Ele precisa escolher perguntas relevantes, interpretar conjuntos de dados menos organizados e decidir quais ferramentas utilizar para explorar essas informações. Esse deslocamento é essencial porque aproxima o aprendizado da forma como o trabalho com dados acontece fora do contexto acadêmico.
A pesquisa orientada representa o primeiro passo nessa transição. Ela não significa apenas buscar respostas prontas na internet. Significa aprender a formular perguntas técnicas adequadas e localizar referências confiáveis que ajudem a responder essas perguntas. Ao investigar conceitos adicionais, comparar abordagens diferentes e testar soluções alternativas, o estudante começa a construir autonomia intelectual. O banco de dados deixa de ser um conteúdo transmitido e passa a ser um campo de exploração.
As listas de exercícios desempenham um papel diferente nesse contexto. Elas funcionam como um espaço intermediário entre a explicação guiada e a prática independente. Ao resolver sequências de problemas relacionados, o estudante aprende a reconhecer padrões estruturais nas consultas. Certas operações deixam de parecer novas a cada tentativa e passam a formar repertório. Esse repertório é o que permite resolver situações inesperadas com segurança posteriormente.
Os mini projetos ampliam ainda mais essa experiência porque introduzem continuidade no trabalho com dados. Em vez de resolver exercícios isolados, o estudante passa a lidar com um conjunto de decisões encadeadas. Precisa modelar tabelas, inserir dados, construir consultas e interpretar resultados dentro de um mesmo contexto. Esse tipo de atividade aproxima o aprendizado da lógica de desenvolvimento real, onde cada escolha influencia as próximas etapas.
Os desafios de SQL ocupam um lugar especial nesse processo porque estimulam a criatividade técnica. Diferente de exercícios tradicionais, eles frequentemente apresentam problemas que podem ser resolvidos de várias maneiras diferentes. Ao experimentar soluções alternativas, o estudante desenvolve sensibilidade para eficiência, clareza e elegância estrutural nas consultas. SQL deixa de ser apenas um conjunto de comandos corretos e passa a ser uma linguagem com múltiplas estratégias possíveis.
As atividades colaborativas introduzem uma dimensão ainda mais importante: o trabalho coletivo sobre estruturas compartilhadas. Em ambientes reais, bancos de dados não são construídos individualmente. Eles fazem parte de sistemas mantidos por equipes. Aprender a discutir modelagem com outras pessoas, interpretar consultas escritas por colegas e documentar decisões estruturais cria habilidades que dificilmente aparecem em exercícios solitários. O banco passa a ser entendido como uma infraestrutura comum, não como uma ferramenta pessoal.
No cenário contemporâneo, essas práticas também assumem formatos novos. Trabalhar com datasets públicos disponíveis em plataformas abertas permite explorar informações reais produzidas fora do ambiente acadêmico. Participar de desafios de consulta estimula raciocínio rápido sobre estruturas desconhecidas. Construir um portfólio técnico transforma exercícios em evidências concretas de aprendizado. Criar dashboards experimentais aproxima o banco de dados de contextos analíticos onde informação precisa ser interpretada visualmente.
Quando essas atividades são incorporadas à rotina de estudo, o aprendizado deixa de depender exclusivamente da sequência formal das aulas. O estudante passa a desenvolver uma relação direta com os dados. Em vez de esperar instruções, começa a formular suas próprias perguntas. E é nesse momento que o banco de dados deixa de ser apenas conteúdo de curso e passa a se tornar ferramenta de investigação permanente.
Referências centrais de teoria de banco de dados
Database System Concepts
Este é um dos livros mais importantes da área. Ele fundamenta conceitos como arquitetura de SGBD, normalização, transações, controle de concorrência e armazenamento físico. Grande parte da explicação sobre estruturas internas do banco vem diretamente dessa tradição teórica.
Designing Data-Intensive Applications
Este livro é hoje a principal referência moderna para compreender sistemas distribuídos, pipelines de dados, consistência, replicação, streaming e arquitetura orientada a eventos. Sustenta especialmente os trechos do curso sobre conectividade entre bancos, Kafka, processamento distribuído e sistemas analíticos.
Referências sobre SQL e desempenho
SQL Performance Explained
Fundamental para entender índices, planos de execução, otimização de consultas e comportamento interno do banco. A base conceitual das explicações sobre performance e estrutura física aparece aqui.
The Art of PostgreSQL
Referência moderna para uso profissional de PostgreSQL. Influencia diretamente as partes do curso sobre instalação de ambiente, modelagem aplicada e escrita de queries expressivas.
Referências estruturais clássicas de modelagem de dados
Embora não tenham sido citadas nominalmente antes, a base da modelagem apresentada no curso deriva diretamente destas tradições:
Database Design for Mere Mortals
Excelente para compreender modelagem conceitual aplicada ao mundo real.
An Introduction to Database Systems
Uma das obras mais importantes da teoria relacional moderna. Influencia diretamente conceitos como integridade referencial e normalização.
Referências modernas para engenharia de dados e analytics
Fundamentals of Data Engineering
Explica pipelines, ingestão, modelagem analítica e arquitetura contemporânea de dados. Sustenta especialmente as partes do curso sobre conectividade entre sistemas.
Analytics Engineering with SQL and dbt
Base conceitual para transformação analítica moderna com SQL.
Documentação técnica oficial recomendada (leitura contínua)
Estas documentações são consideradas leitura obrigatória na prática profissional:
Documentação oficial PostgreSQL
Documentação oficial MySQL
Documentação oficial SQL Server
Documentação BigQuery
Documentação Snowflake
Documentação dbt
Documentação Apache Kafka
Documentação Apache Spark
Documentação Apache Airflow
Referências conceituais de arquitetura de sistemas
Patterns of Enterprise Application Architecture
Base estrutural para compreender camadas de acesso a dados, ORM, repositórios e serviços.
Referência pedagógica citada no material original
Paulo Freire
A frase utilizada no encerramento do material original (“ensinar não é transferir conhecimento...”) fundamenta a abordagem metodológica adotada ao longo do curso: aprender banco de dados como construção ativa de raciocínio estrutural.
Como essas referências foram usadas na construção do curso
A estrutura completa que desenvolvi neste material combina três tradições principais:
a tradição clássica de bancos relacionais (Silberschatz, Date)
a tradição moderna de arquitetura distribuída (Kleppmann, Reis)
a prática contemporânea de SQL analítico e pipelines (Winand, Fontaine, dbt docs)
Muito bom seu texto sobre banco de dados, parabéns!!!